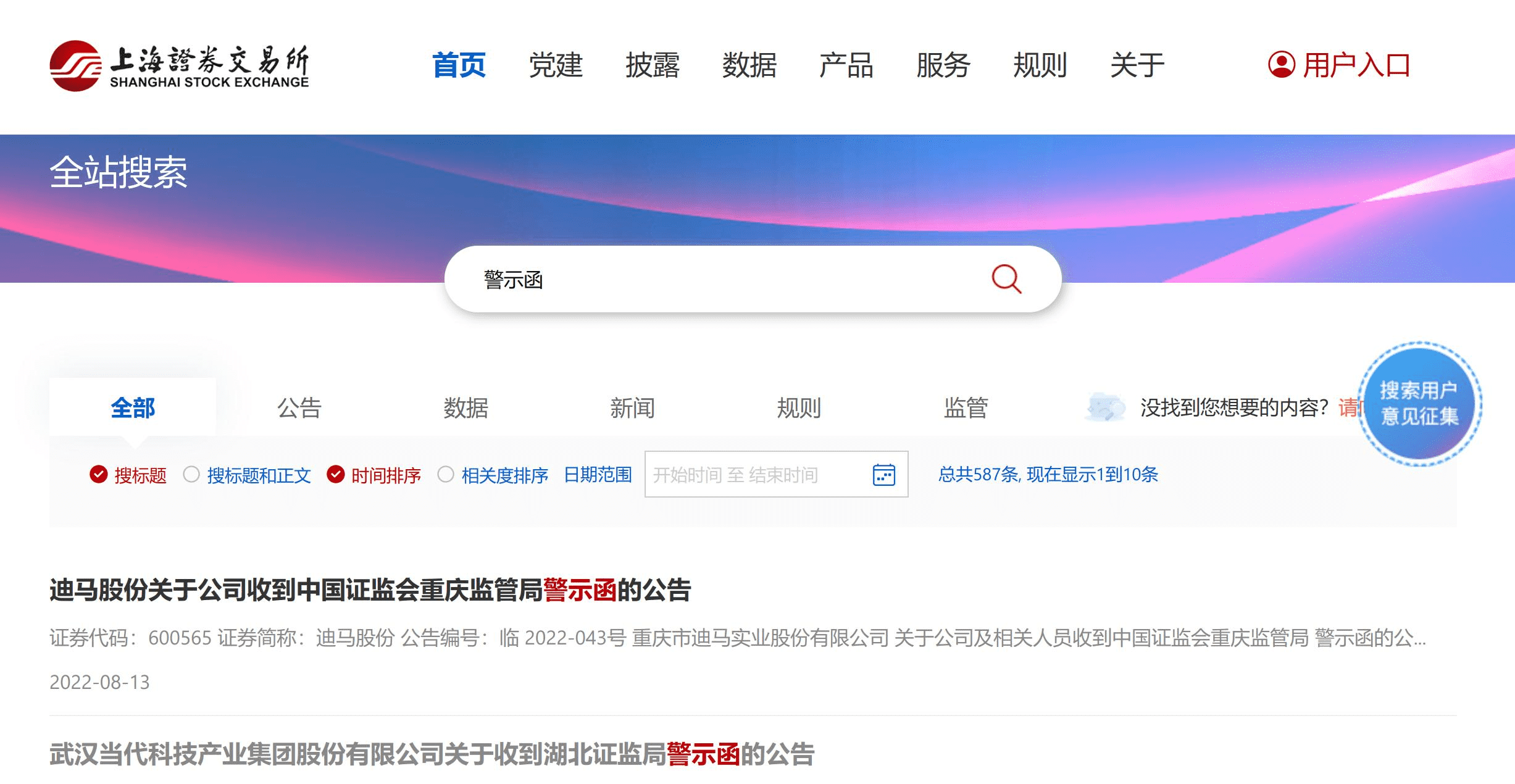
上交所警示函批量下载
陈版主答疑文章使用的爬虫失效了,暂时没有更新,这周我抽时间更新下,再为大家每天推送。
昨天文章有朋友留言让分享下上交所警示函下载的工具,
虽然写这个代码不难,但还是可以和大家分享下思路。
任务拆解
当我们想做一个工具的时候,首先需要梳理出逻辑。
也就是先手工操作一遍,把一个大任务拆分成可执行的小任务。
大目标
比如,我们的目标是登录上交所网站,输入“警示函”关键字,点击查询,
点击一个列表页,将显示的 PDF 下载下来,然后复制其中的文字到我们保存的文件中。
这个流程有好几步,很多人刚开始学习的时候不太意识到这是一个大目标,
你直接对别人说:“哎,把最近几年上交所警示函内容帮我整理出来。”
别人是茫然的,不知道怎么做。
同样的,你自己也不知道,你可能只能在浏览器上搜索:“批量下载上交所警示函”
如果运气好,别人做过,可能会有现成的轮子,否则,你就又卡住了。
要知道,对于一个大目标我们是很难实际落地执行的。
小任务
那么,要想实现我们的大目标,最好的方法就是任务拆解。
- 获取网页信息(包括 PDF 下载链接)
- 下载 PDF 文件
- 解析 PDF 文件
- 保存数据
当我们能把任务进行拆解后,难度就自然极度下降了,
我们现在只需要针对这 4 个问题写函数完成。
我们以最简单的解析 PDF 文件为例,
啊?为什么这个是最简单的?因为之前在一篇文章中学过,用 pdfplumber
库解析 PDF 。
import pdfplumber
def extract_pdf(path):
"""提取pdf文字内容"""
with pdfplumber.open(path) as pdf:
pages = pdf.pages
text = ''.join(page.extract_text() for page in pages)
return text你看 4 个问题,我们就解决了一个。简单吧?
周而复始
需要注意的是,上交所给的 PDF 绝大部分是文本的,一小部分的是扫描图片的。
这个代码只能解析文本的 PDF ,如果你想完全解决,那么我们又可以任务拆解的方法,
将3.解析PDF文件分解为:
3.1 解析文字类PDF
3.2 解析扫描类PDF
啊?扫描类的 PDF 文件我怎么解析呢?要么你在浏览器上搜索下有没有这个解决办法。
要么我们再进一步拆解,我们可以把扫描的 PDF 保存为一张张图片,再用 OCR 去识别图片:
3.2.1 PDF拆分成图片
3.2.2 OCR识别图片为文字
每一个如果不会,就去搜索解决,搜索没有直接答案的,就看能不能拆成更小的任务,
循环往复,直到找到解决问题的方法。
搜索问题及笔记记录
通过上面的步骤,我们能把一个复杂任务转换为简单任务。
这也是数学中的化归思想。
这些简单任务,有些我们可能已经会了,有些可能不会。
对于不会的,我们就需要去检索了,也就是问 度娘。
这个真就是熟能生巧了,查得多了,就有技巧了,基本小的问题你都能解决。
当你查到后,一定要把有价值的问题,记录到你的笔记中,
你看上次我们在“ python 提取关键审计事项”的文章中用到的pdfplumber,
今天又用上了。
查一次你可能会忘记,当你记录下来,下次遇到你就节约了检索的时间,
多遇到几次,你就彻底掌握了,这个就是知识习得的过程。
完整代码
其实代码并不重要,有需要的可以自己拿来练习、练习。
import pdfplumber
import pandas as pd
import requests
from urllib.parse import urljoin,urlencode,quote
import os
import pymysql
import time as ttime
def extract_pdf(path):
"""提取pdf文字内容"""
with pdfplumber.open(path) as pdf:
pages = pdf.pages
text = ''.join(page.extract_text() for page in pages)
return text
def download_pdf(url,path,pdf_name):
"""下载PDF文件"""
file_path = os.path.join(path,pdf_name)
if os.path.exists(file_path)==False:
if os.path.exists(path)==False:
os.makedirs(path)
r=requests.get(url)
with open(file_path,'wb') as f:
f.write(r.content)
def get_download_urls(keyword):
"""获取列表信息及PDF下载链接"""
page = 1
url = 'http://query.sse.com.cn/search/getSearchResult.do?search=qwjs&jsonCallBack=&searchword=T_L+CTITLE+T_E+T_L' + quote(keyword) +'+T_R+and+cchannelcode+T_E+T_L0T_D8311T_D8321T_D8348T_D8349T_D8365T_D8703T_D8828T_D8834T_D9856T_D9860T_D9862T_D9888T_D9889T_D9892T_D10004T_D10011T_D10743T_D12002T_D88888888T_RT_R&orderby=-CRELEASETIME&page=%s&perpage=10&_=1660204739688' % page
header = {
'User-Agent':'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.134 Safari/537.36 Edg/103.0.1264.71',
'Host':'query.sse.com.cn',
'Referer':'http://www.sse.com.cn/',
}
response = requests.get(url,headers=header)
json_str = response.json()
total_page = int(json_str['countPage'])
infos = []
for page in range(total_page+1):
ttime.sleep(4) # 暂停的秒数,避免频繁调用
print('获取第%s页信息,共%s页' % (page,total_page))
url = 'http://query.sse.com.cn/search/getSearchResult.do?search=qwjs&jsonCallBack=&searchword=T_L+CTITLE+T_E+T_L' + quote(keyword) +'+T_R+and+cchannelcode+T_E+T_L0T_D8311T_D8321T_D8348T_D8349T_D8365T_D8703T_D8828T_D8834T_D9856T_D9860T_D9862T_D9888T_D9889T_D9892T_D10004T_D10011T_D10743T_D12002T_D88888888T_RT_R&orderby=-CRELEASETIME&page=%s&perpage=10&_=1660204739688' % page
response = requests.get(url,headers=header)
json_str = response.json()
for row in json_str['data']:
title = row['CTITLE_TXT']
print(title)
link = row['CURL']
url = urljoin("http://www.sse.com.cn/",link)
date = row['CRELEASETIME']
time = row['CRELEASETIME2']
file_type = row['MIMETYPE']
id = row['DOCID']
data = {
'title':title,
'url':url,
'date':date,
'time':time,
'file_type':file_type,
'id':id
}
infos.append(data)
return infos
def upload_mysql(connect, cursor, item, table_name):
"""上传字典数据到mysql数据库"""
keys = ','.join(item.keys())
values = ','.join(['%s']*len(item))
sql = 'insert into %s(%s) values(%s) on duplicate key update ' % (
table_name, keys, values)
update = ','.join([key + '=%s' for key in item])
sql += update
try:
cursor.execute(sql, tuple(item.values())*2)
connect.commit()
except:
connect.rollback()
if __name__ == '__main__':
# 使用数据库,如果不将解析的数据传到数据库,可以注释掉,注意修改数据库账号、密码信息
# connect = pymysql.connect(
# host = '127.0.0.1', db = 'book', user = 'root',
# passwd = 'xxxx', charset = 'utf8')
# cursor = connect.cursor()
# table_name = 'chufa'
# 使用数据库,如果不将解析的数据传到数据库,可以注释掉
directory = './pdf' # 下载的pdf文件保存文件夹路径
infos = get_download_urls('警示函')
df = pd.DataFrame(infos)
df.to_excel('下载链接.xlsx',index=False) # 将获取到的列表信息保存到本地
output = []
for row in infos:
url = row['url']
pdf_name = row['title'] + '.' + row['file_type']
try:
download_pdf(url,directory,pdf_name) # 下载PDF
print('下载文件:%s' % pdf_name)
path = os.path.join(directory,pdf_name)
content = extract_pdf(path)
except:
print('下载文件失败')
content = ''
row['content'] = content
# 传数据库,如果不用数据库可以注释掉
# upload_mysql(connect,cursor,row,table_name)由于解析的 PDF 文字很多,直接输出成 Excel 会串行,所以我是在第 4 步保存数据的时候,
把数据保存在数据库中,然后把数据库的表导出成 Excel 。
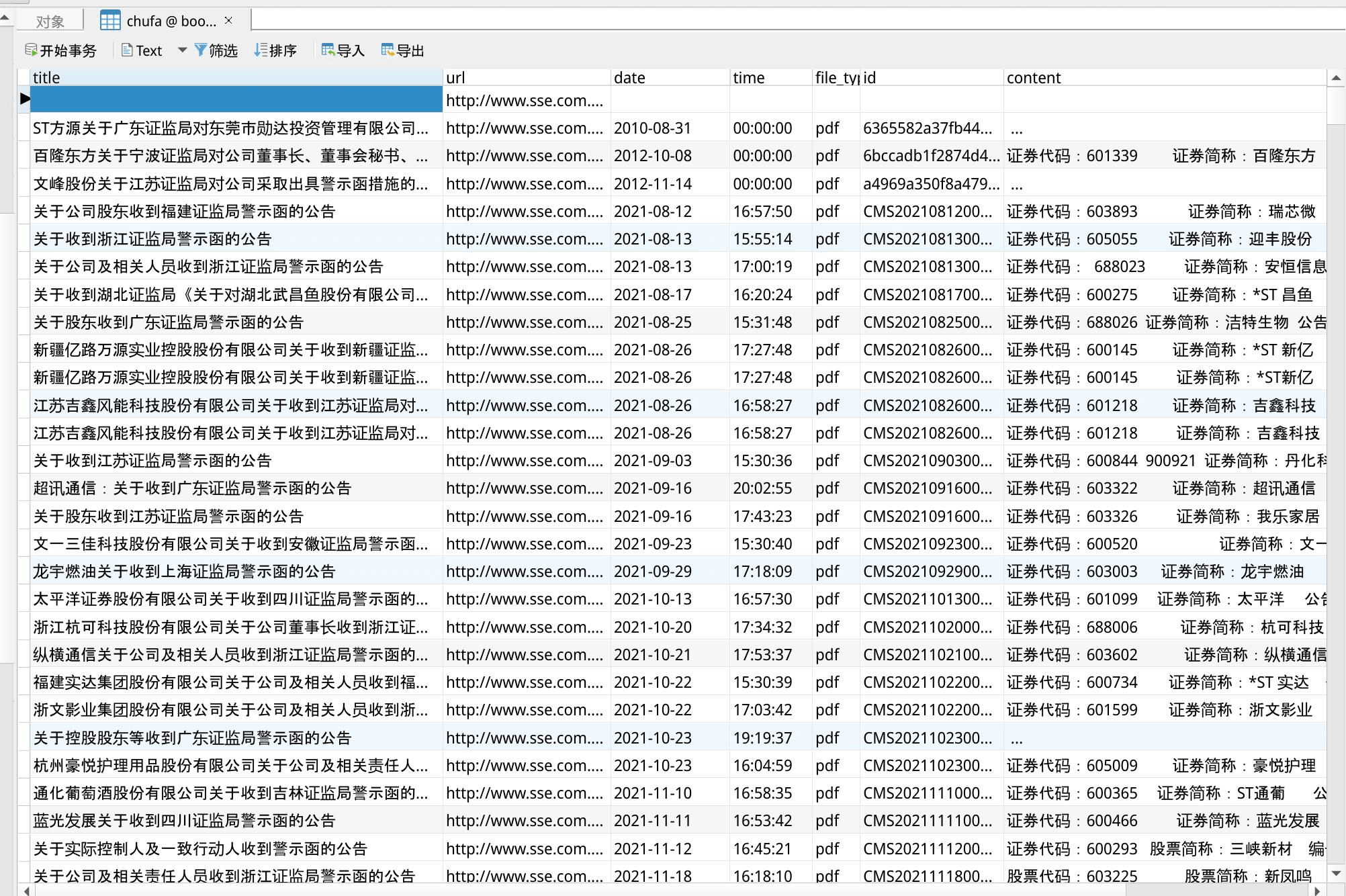
为了让读者能执行代码,我把上传数据库的代码注释了,但是解析的content你就看不到。
如果你会 mysql 数据库,可以把取消注释代码。
如果你想查询其它的关键词,下载 PDF ,可以修改这行代码的关键词:
infos = get_download_urls('警示函')文件信息及PDF下载
我把下载好的信息和 PDF 也打包分享大家,有需要的可以直接下载: