带带弟弟ocr
目录
平时我们想获取一些网页的信息,需要写爬虫,有些网站有各种验证码,增加了我们工作的一些困难。
在上个咨询项目中,我发现了一个识别验证码的库,非常好用,推荐给有需要的朋友。
它的名字就叫带带弟弟OCR ,看名字就是拯救我们这类小白的。
他不用安装什么深度学习框架,不需要搞一堆训练集训练,直接安装就可以使用。
安装
pip install ddddocr识别数字验证码
这里我们拿个最简单的数字验证码看看

我们只需要几行代码,就可以完成数字验证码的识别:
import ddddocr
ocr = ddddocr.DdddOcr(show_ad=False)
with open("./images/2022-09-17_23-09-27_screenshot.png", 'rb') as f:
image = f.read()
res = ocr.classification(image)
print(res)简单、易用,准确率极高。

在 github 上的介绍页面上,经过大家测试对于这些数字验证码都是可以准确识别的。
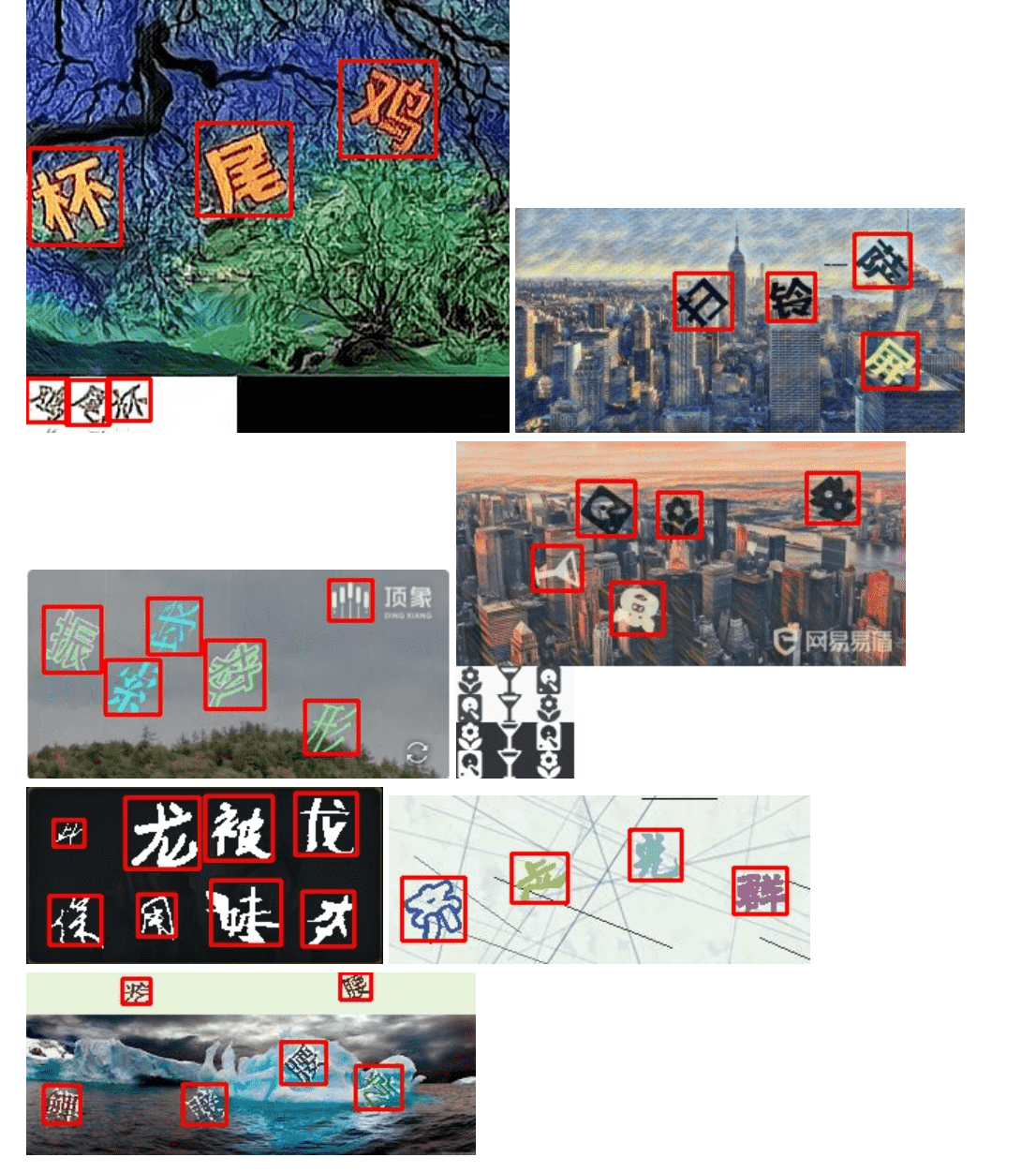
点选验证码
在介绍页面,这种点选的验证码,也是可以识别的。
滑块验证码
竟然还支持滑块验证码的识别,真香!

官方文档
这个ddddocr的官方文档地址:
https://github.com/sml2h3/ddddocr
对于很多需要破解验证码的网站来说,这个库真是神器。