mysql导入csv文件少行原因探索
在 IT 审计的数据分析中,如果数据量稍微大点,获取数据我们一般都是 csv 文件。
如果客户给了很多 Excel 文件,我一般也会批量转成 csv 文件合并成一个,
再将数据导入到 Mysql 数据库中。
我自己在导完数后,一般会对行数进行校验,看原文件多少行,以及导入数据库多少行,确认数据导入正确。
昨天我发现导入数据库后的行数比 CSV 文件行数少,且没有报错。
其实之前我也遇到过两次这种问题,但当时数据量是上亿行和千万行,实在难以找到原因。
昨天的一个数据只有 4 万行,为了了解原因,用二分法经过大概 20 次数据对比,肉眼找到出问题的那行。
发现原因是字段内有换行符 。
换行符
这里我们举一个例子:

这张表里有两行数据,其中第二行“商品名称”中有换行符。
我们将数据导入到 mysql 数据库会看到也是只有两行
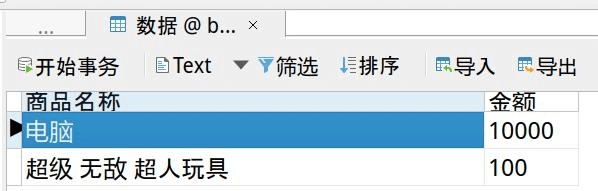
但是你用命令行wc -l查看数据行数或者用记事本打开就会有 4 行数据:

这就是为什么我们查看 csv 的行数比我们导入数据库中的行数多的原因。
那么我们看看解决方法。
去除CSV文件中的换行符
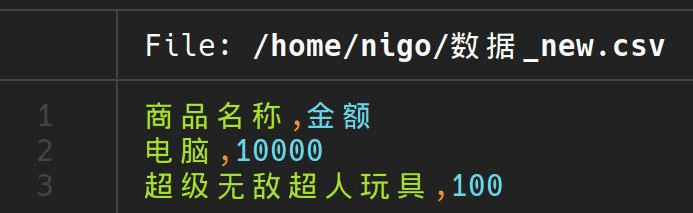
我们可以使用 pandas 库读取 csv 文件,并用 replace 函数将换行符\n替换为空。
import pandas as pd
df = pd.read_csv('数据.csv')
df = df.replace('\n', '', regex=True)
df.to_csv('数据_new.csv',index=False)可以看到输出的文件中换行符被替换了。
当然,一般我们处理的数据会非常大,如果这样一次性读取会超过电脑内存,这时我们可以使用分块读取,分块处理。
import pandas as pd
def replace_newlines(input_file, output_file):
chunksize = 10**6 #1MB
flag = True
for chunk in pd.read_csv(input_file, chunksize=chunksize, engine='python'):
# Process each chunk
chunk = chunk.replace('\n', '', regex=True)
# write the chunk to the output_file
if flag:
chunk.to_csv(output_file,mode='w',header=True,index=False)
flag = False
else:
chunk.to_csv(output_file,mode='a',header=False,index=False)
if __name__ == "__main__":
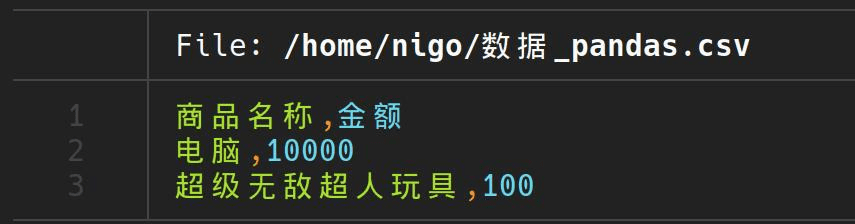
replace_newlines('数据.csv','数据_pandas.csv')我们可以看到数据也被正确处理了,当然,这里没有拿大数据来演示。
去除Excel文件的换行符
如果给的 Excel 文件,需要转成 CSV 文件,那么你仍然可以使用上面 pandas 的处理方法,区别只是读取 csv 文件变成了读取 excel 文件。
使用pd.read_excel()即可读取 Excel 文件。如果想输出成 Excel ,可以使用pd.to_excel()即可。
当然,我们还可以使用更简单的方法。
python有个xlsx2csv库,可以直接将 Excel 转成 csv 文件。
安装方法:
pip install xlsx2csv
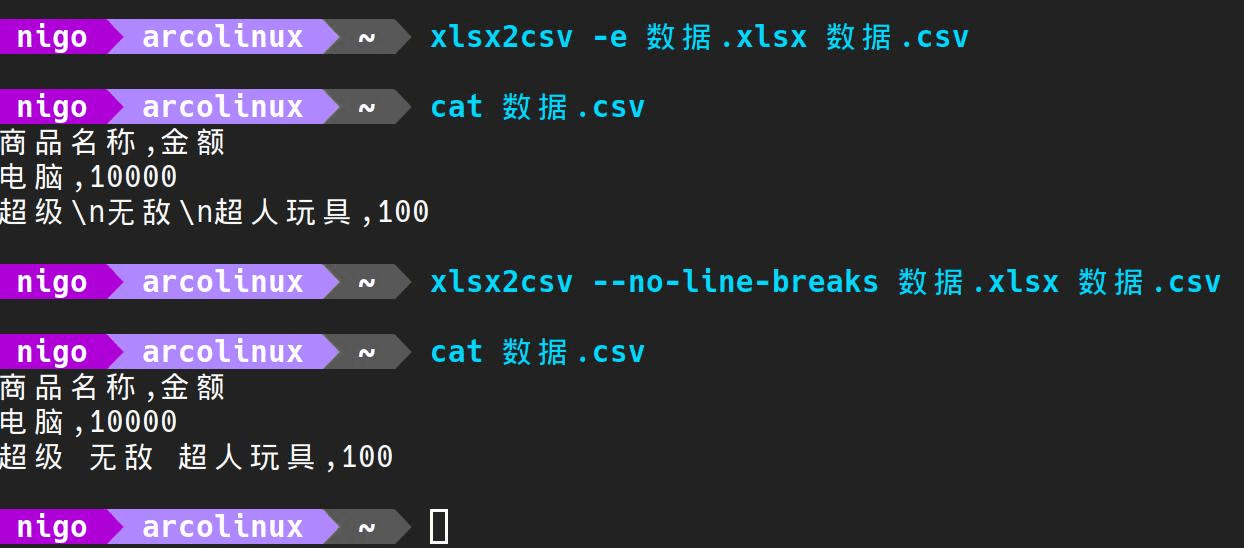
我们可以看到直接这样转换, csv 文件中还是会有换行符。
通过xlsx2csv --help可以查看帮助文档。
我们可以看到有两个参数可以使用:
-e :会将\r\n\t等符号变成字符串。
--no-line-breaks :会将换行符替换成空格。
(注: windows 换行符为\r\n, Linux 换行符为\n)
因此我们只需要使用这两个参数即可。
结语
其实昨天如果不是为了找这个原因,也可以手工一个一个 excel 去导入。
但这样其实自己是没有任何收获的。
4万多行,二分法肉眼才找到出问题那行。
耗费了一晚上研究清楚这个问题产生原因,将来各种情况的解决方法,无疑以后再次遇到的时候将直接上手解决。
重剑无锋,大巧不工。