5000元笔记本处理8亿行数据量
前面提到过在上上个项目中,客户给了订单数据的数据库,有 500 多张表。
让 chatgpt 写了段批量将数据下载的代码:
import pymysql
import pandas as pd
# 建立 MySQL 数据库连接
conn = pymysql.connect(
host='your_host', db='your_db_name', user='user',
passwd='password', charset='utf8')
# 循环遍历每个表,导出为 CSV 文件
for i in range(512):
try:
print("开始第%s张表" % i)
table_name = f"chapter_orders{i}"
query = "select * from {table_name}"
df = pd.read_sql(query, conn)
file_name = f"{table_name}.csv"
df.to_csv(file_name, index=False)
except:
pass
# 关闭数据库连接
conn.close()但是同事并没有这么做,因为她笔记本就 256G 的硬盘,空间不够。
而她在客户提供的 msyql 数据库中,把每几十张表需要的字段合成一张大表,大概合了 8 张表。
但是后面发现执行的语句有误,需要重新跑所有的数据,而刚好她在合并表的并没有加需要的字段。
让她本地搞吧,但是一张表下载下来 200 多M, 500 多张表要 100 多G,她电脑根本不行。
就算她下载下来,自己笔记本用 mysql 也搞不定这么大的数据量。
让她在客户提供的数据库上重新再来一遍吧,又不知道要费多少工夫。
头疼。
我自己来吧。
先是执行上述 python 代码,将 500 多张表下载到我笔记本上,花费大概 30 多个小时。
然后在笔记本上开启大数据杀器, clickhouse 。
写个 Bash 脚本,批量将 500 多个 CSV 文件导入clickhouse.
for file in *.csv; do
sed -n '2,$p' "$file" | clickhouse client --query 'insert into chapter FORMAT CSV' --date_time_input_format=best_effort
echo "$file"
doneclickhouse导入数据比 mysql 快多了,大概 200 多M的 csv 文件,平均 2 秒一个。
用 DBeaver 连接 clickhouse ,就可以写 SQL 了。
看一下数据量:
select count(1) from chapter;共计:895,049,813 接近 9 亿行数据。
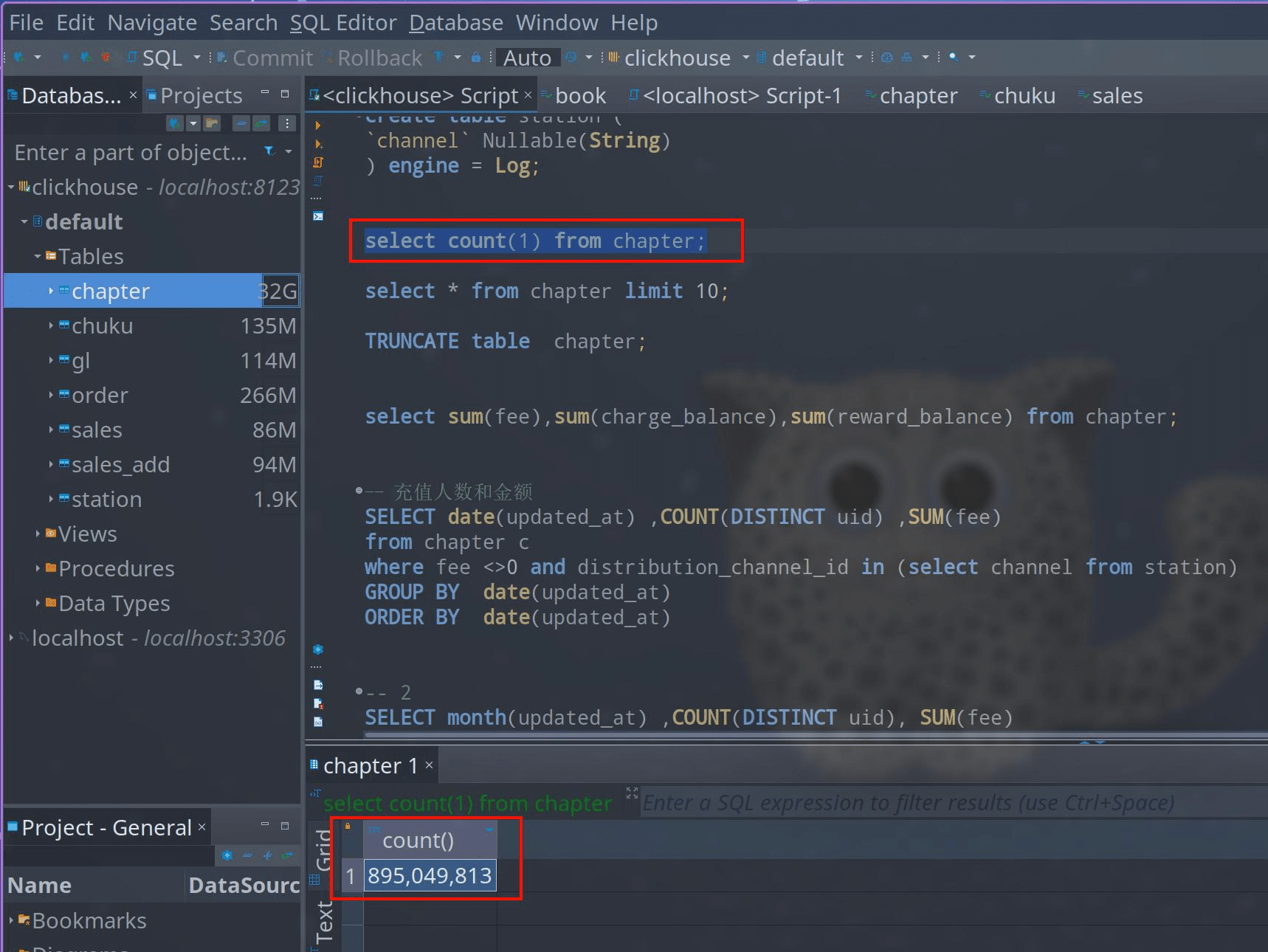
只需要 2 秒就能跑出上面结果,很难想象用 mysql 跑个 9 亿的数据是怎么样。而且还是我这个 2019 年出厂的联想小新 pro 的笔记本上。
在笔记本上跑个稍微复杂点的 SQL ,也一般不超过 30 秒就出结果。
clickhouse,YYDS。
只要是上千万的数据,我感觉用它都更加方便,省时。
再比如上个项目,同事两个百万级的表也 join 反应不出来,电脑直接崩死。
有时候感觉心累,反应不出来,我也不能怪人。电脑容量不够,我也没法提供电脑。有些客户要个数据都难,更别说让他们提供服务器了。就算提供服务器了,给你搭建个 mysql 环境,大数据量下,照样跑不出来。
其实想想,不会也有不会的好处,没有哪个项目会因为技术问题而停滞。
会有会的做法,不会有不会的做法。
开心就好。