利用AI生成图片
前面玩过了 chatgpt ,这两天我又试用了下 AI 在绘图方面的效果。
我尝试了两款工具:=Midjourney= ,=stable-diffusion-webui= 。
Midjourney 是一个商业应用,注册后在浏览器上输入一些prompt 提示词,就可以生成 4 张图片。
你可以选择其中一张不断深度调整,得到你想要的。
比如我用翻译软件翻译了“一个骑在火箭上的审计师,超现实”后,输入“An auditor riding a rocket in the pride of space. surrealism –ar 2:1”。
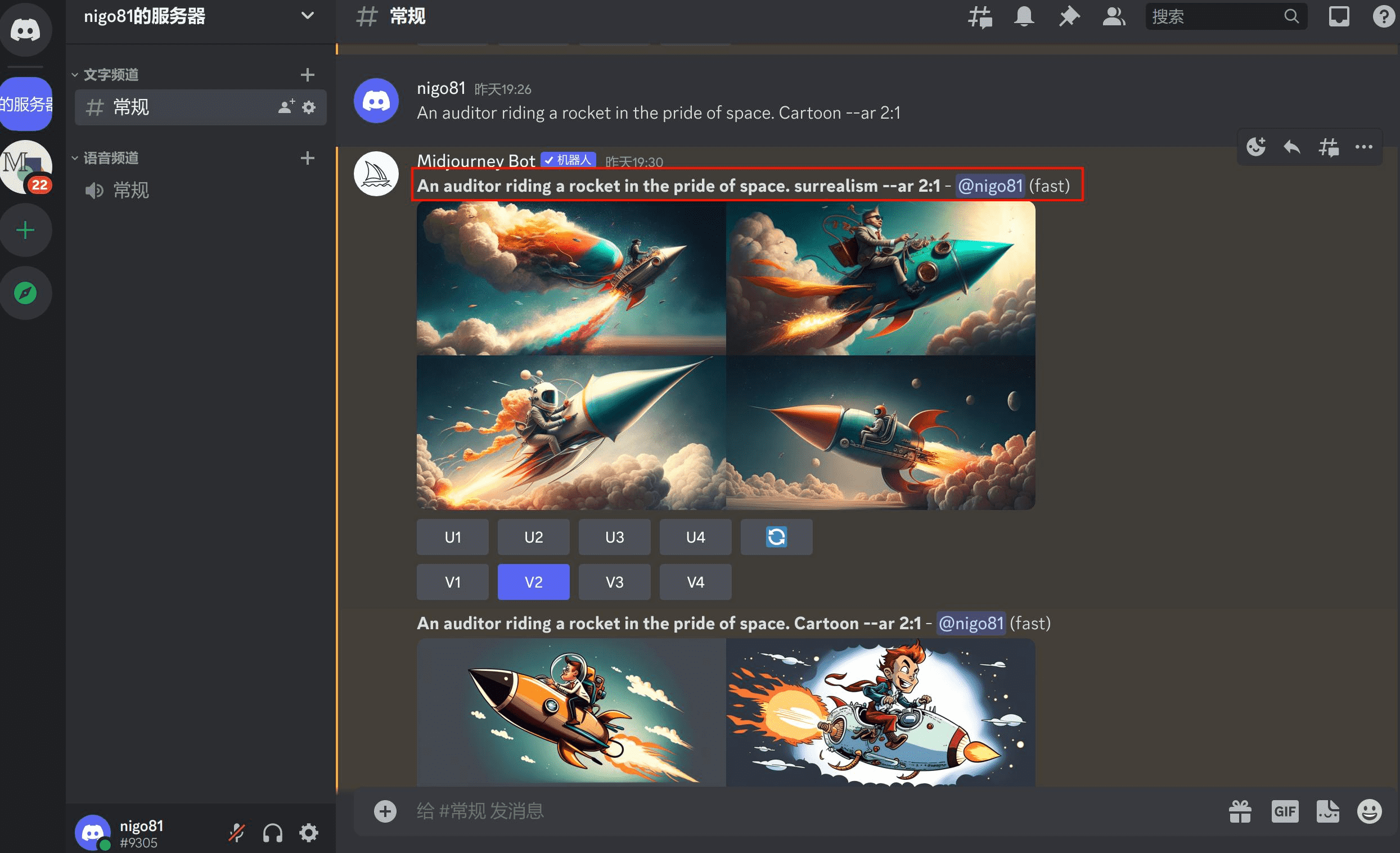
就可以给我非常不错的图案。
不过 Midjourney 是一个商业网站,免费额度有限,而且免费生成的图不能商用。
不过它确实最容易上手,只需要看看 B 站上的教学视频,能正确上网就可以使用,出的图也非常不错。
然后,我又试用了开源免费的stable-diffusion-webui, 它可以在本地部署,需要有比较好的显卡。
正好我台式机有张 3080 显卡,照着 github 上的安装教程进行了安装。
这个过程稍微比较复杂,需要的时间也比较久。
安装好后,可以在本地的浏览器上打开,同样的可以输入一些文字,直接出图。
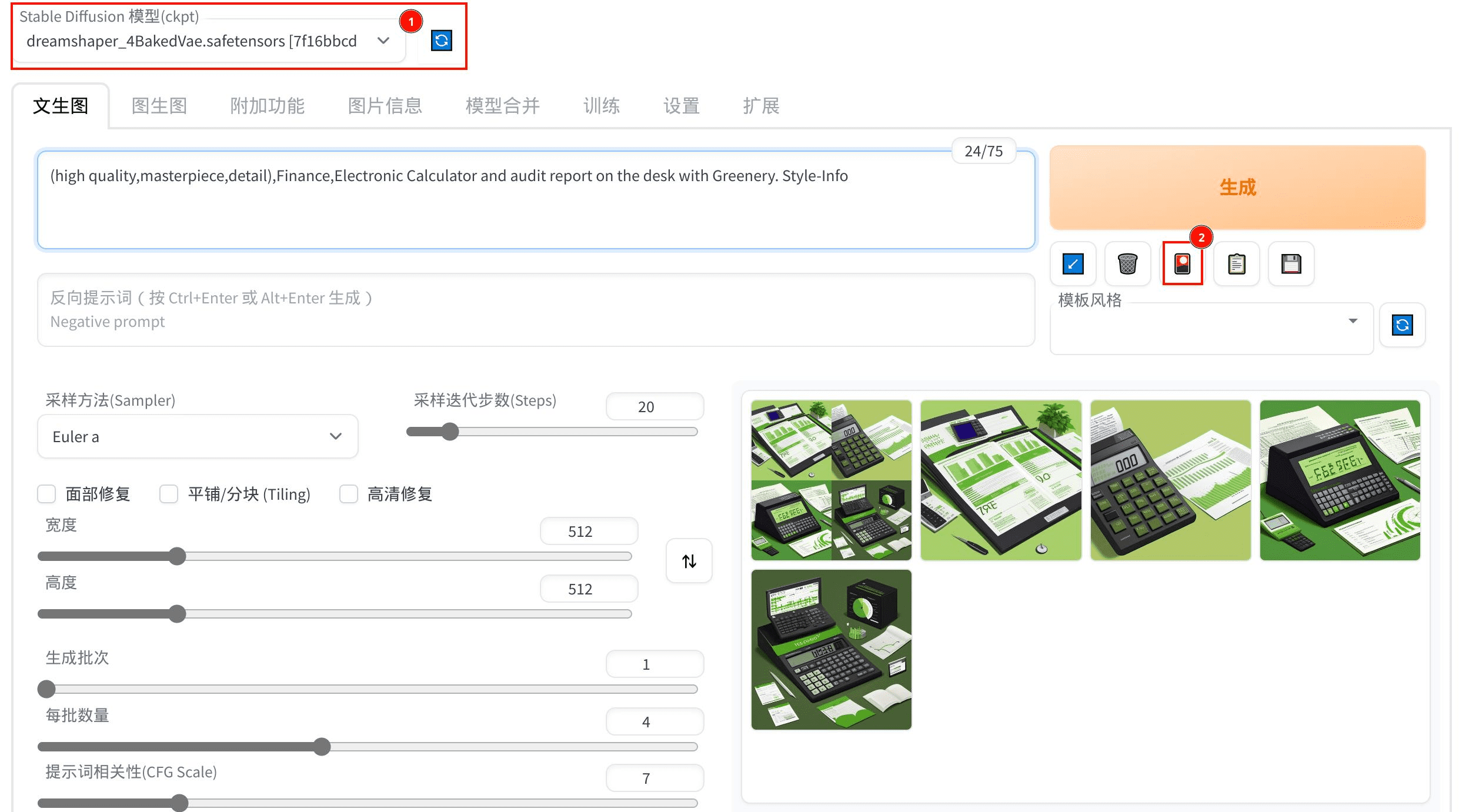
刚安装的时候使用的模型出的图不是很好,可以在civitai 网站上找一些模型。
这个过程比较麻烦,需要在网上看大量教程。
不过我也就折腾了下面三个:
- Stable Diffusion 模型( modules ):不同的图像生成算法。
- Embedding 嵌入式:将某个风格的描述文字 prompt 用一个词代替,可以重复使用一种风格。
- Lora: 生成不同风格的算法。
后面两个在点击“生成”下面像照片一样的按钮后就可以看到相关信息。需要在civitai 网站上去下载对应的包,拷贝到本地对应文件夹中就可以使用。
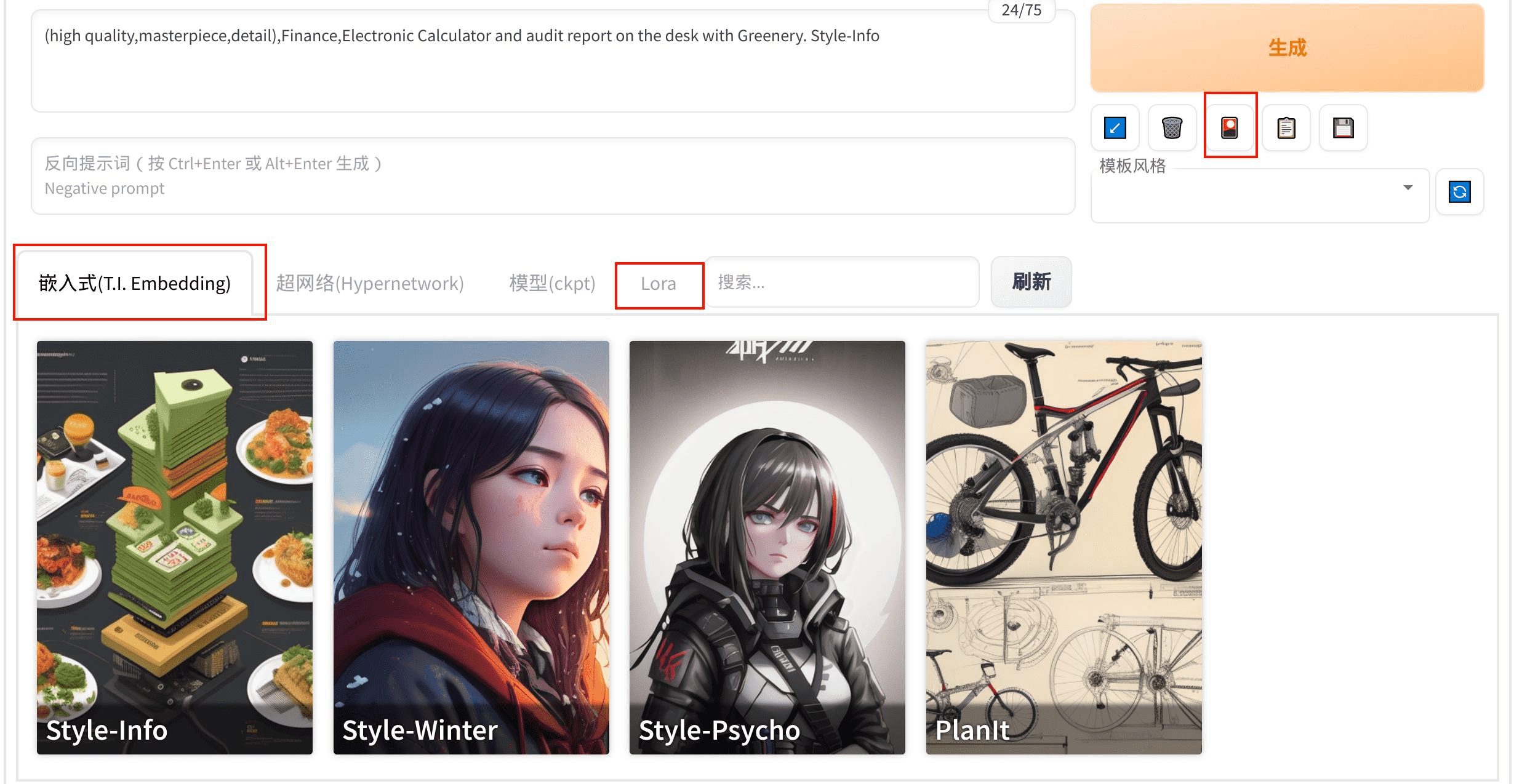
我看了很多网上教程,也就只折腾了上面三项内容,不过这已经让我感受到他的强大了。
比如,我想生成“一张桌子上有电子计算器和审计报告”的图片,直接输入:
(high quality,masterpiece,detail),Finance,Electronic Calculator and audit report on the desk with Greenery. Style-Info大概 4 、5秒就给我出了 4 张图(主要看显卡性能)

基本上 1 、2秒就可以出一张图,真的太强了。
在 civitai 上你可以看到太多风格的图了,我们都可以在本地上生成类似的。
展示下今天生成的部分图片:

我玩了一天,已经沉迷其中了。