IT审计可以扔掉mysql了,新神器duckdb来临!
一个朋友给我推荐了一个数据 duckdb 让我去试用下。
我试用后,感觉作为平时在本地进行数据分析的 IT 审计来说,完全可以丢掉mysql,sqlserver这些数据库了。

先说下 duckdb 的优势:
- 不需要安装服务器端。类似 sqllite 将数据存储在文件中,不需要安装服务器端。
- 列式数据库。 mysql 是行式数据库,而 duckdb 和 clickhouse 一样是列式数据库,且运行时调用所有 CPU 计算性能能比 mysql 快上百倍。
- 大数据量。平时我们使用自己笔记本(一般轻薄本),如果使用 mysql 基本上上千万行就有点处理慢了。而 duckdb 我测试了下 8 亿行数据也在 20 秒内反应出来。
- 导数方便并快速。
- 使用 sql 语句。你会 sql 语句,就可以马上上手,基本上没有太大的迁移成本。
- 全平台。支持windows,linux,mac。
- 开源免费。
- 可以和 python 等编程语言无缝结合。
我使用了下,感觉非常智能、强大、粗暴。
后面我可能会写一系列教程来介绍它,让大家目前还在用 mysql 的朋友可以无成本迁移到 duckdb 上来。我觉得这是值得的。
这里我先简单给大家说明下有多简单。
图形化管理工具
使用 mysql 的朋友可能一般都会用 navicat 等图形化管理工具。 duckdb 我们可以使用 dbeaver 图形化管理工具,它是开源免费的。
安装好后 dbeaver 后,新建一个连接,选择 duckdb ,点击 next 。
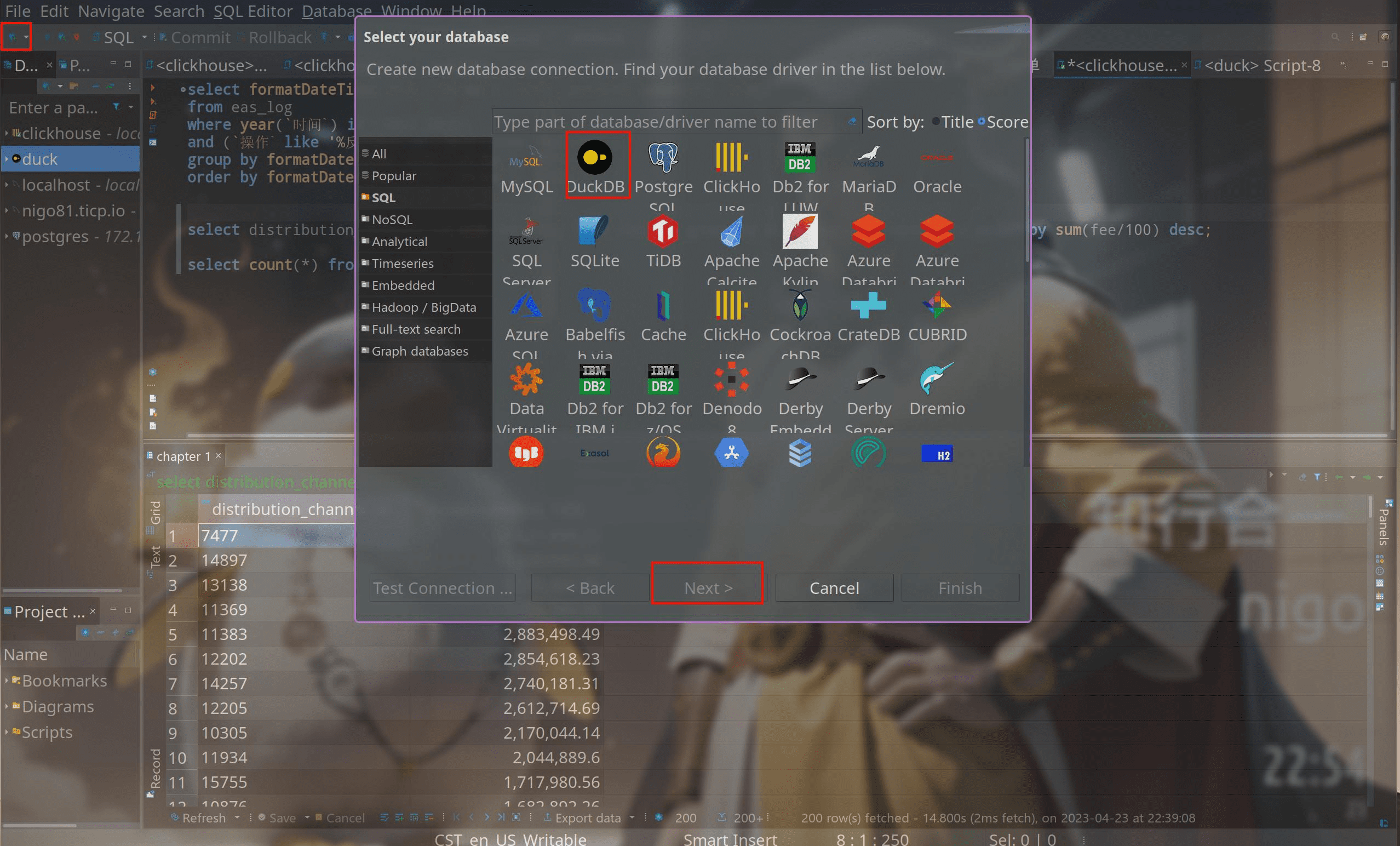
要知道 duckdb 不需要安装服务器端,只需要创建一个文件,我们输入一个文件名。点击下Test Connection将会自动安装对应驱动。
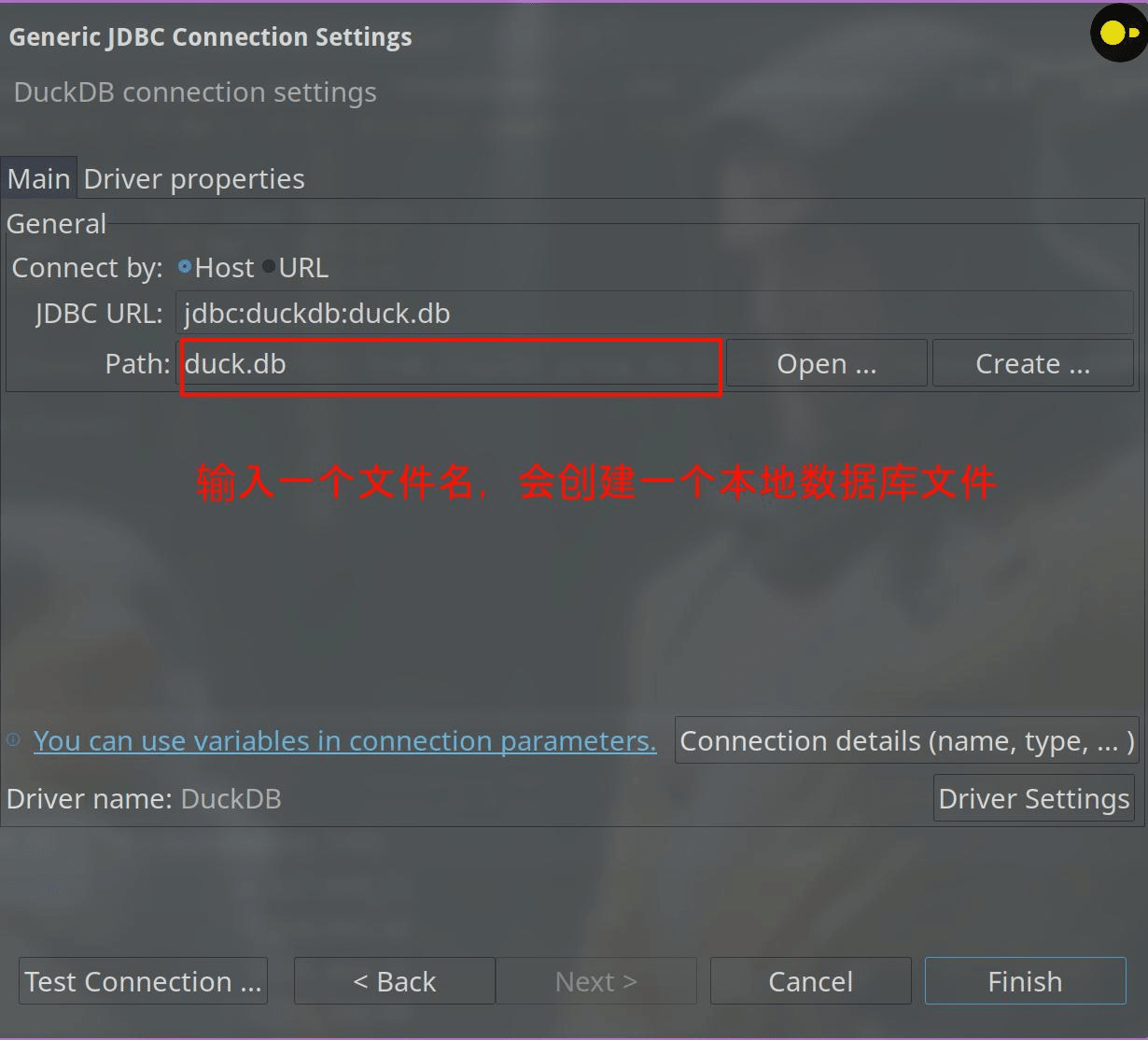
安装好驱动后,直接 Finish.
这就安装好了!安装好了!
我相信安装过mysql+navicat或者 sqlserver的人应该能体会到,这个安装有多简单!
导入数据
很多人在使用 mysql 的时候觉得使用 navicat 导入向导比较方便,主要是这可以省去建表的时间,但当你用导入向导的时候速度非常慢。
比如我这里有个销售订单的 csv 文件,一共2.6G。我只需要写语句:
create table 销售订单 as select * from read_csv_auto('/home/nigo/销售订单.csv')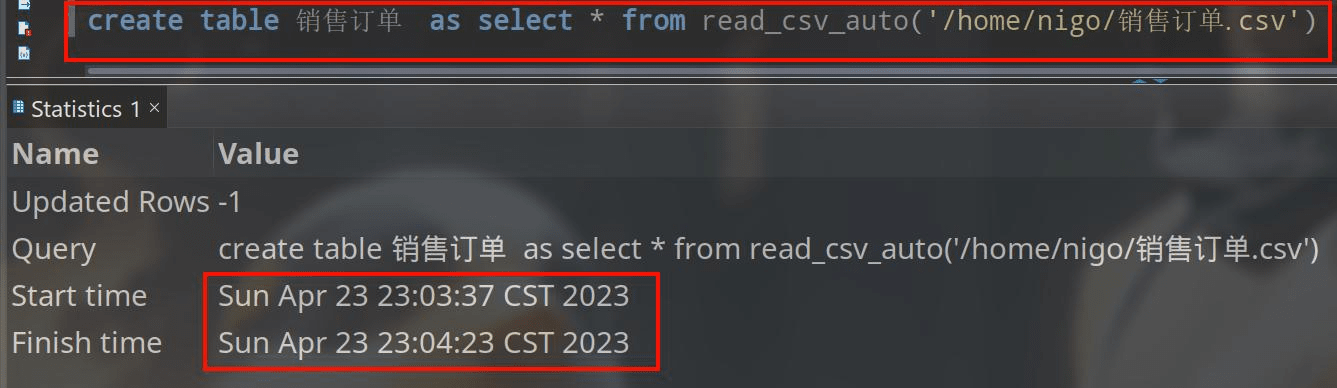
一共花费 46 秒。
虽然这导入数据速度比 clickhouse 要慢不少,但比 mysql 不知道快了多少倍。
我经常看到同事导一个几 G 的数据用 navicat 导入向导在那里傻等着,估计半个小时往上。
你双击下刚新建的表,可以看到每个字段都按最合适的数据类型给创建好了,这不比自己写建表语句香么?
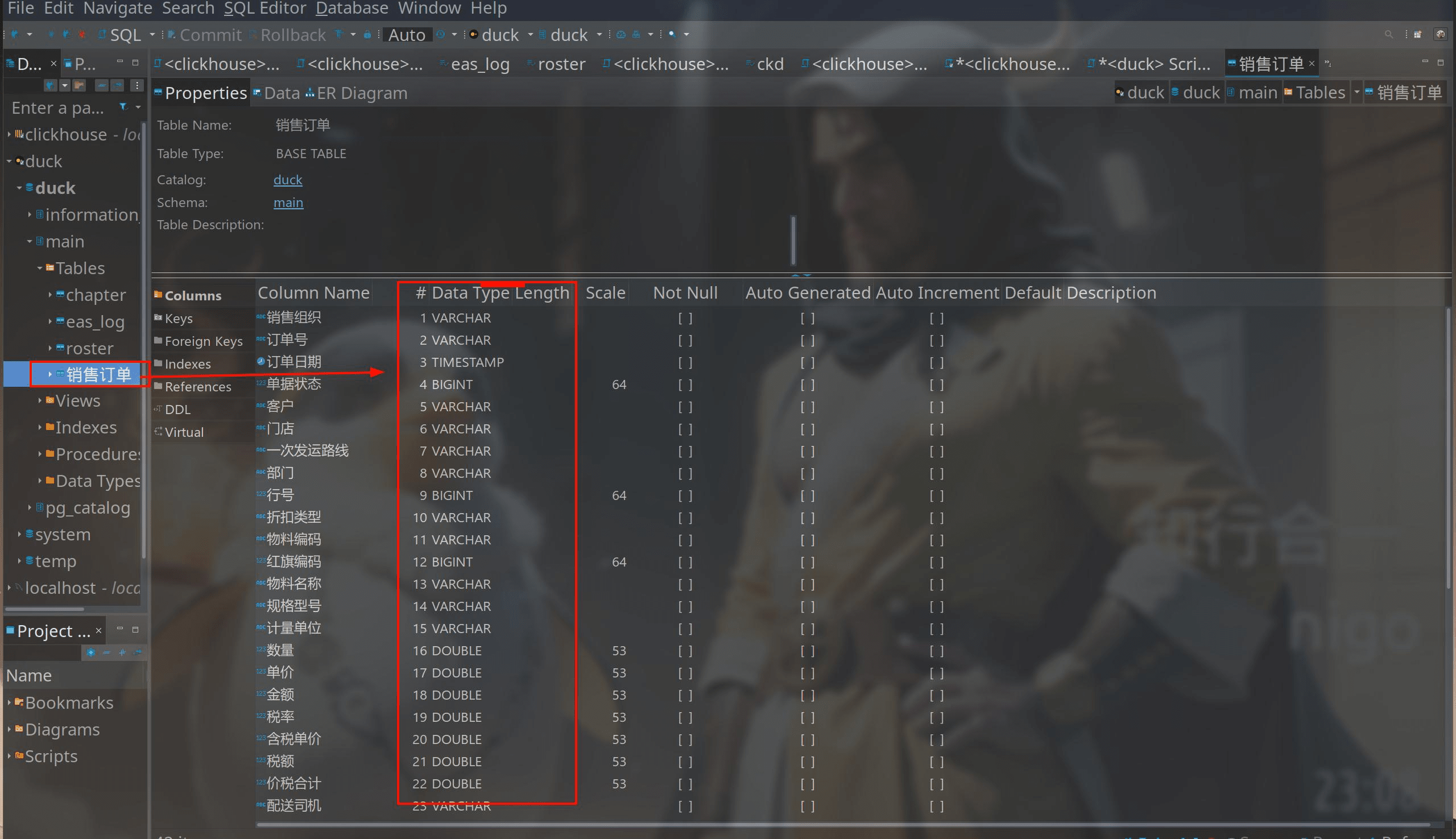
这也太智能了。
处理数据量
我相信大部分用自己笔记本运行 mysql 做数据分析的,最多也就处理个千万行。
并且当千万行的时候,笔记本很可能跑不出来了。
那么 duckdb 可以跑多少数据量呢?
前面我用 clickhouse 在2019年产的 5000 块的联系小新pro 笔记本上跑过 8 亿行数据。
今天,我们也直接上 8 亿数据。
但是这个数据量,我用 dbeaver 跑的时候直接崩溃。不过这不是 duckdb 的问题,而是 dbeaver 的问题。
我直接使用 pyhton 跑。
我们先跑个总的数据量:
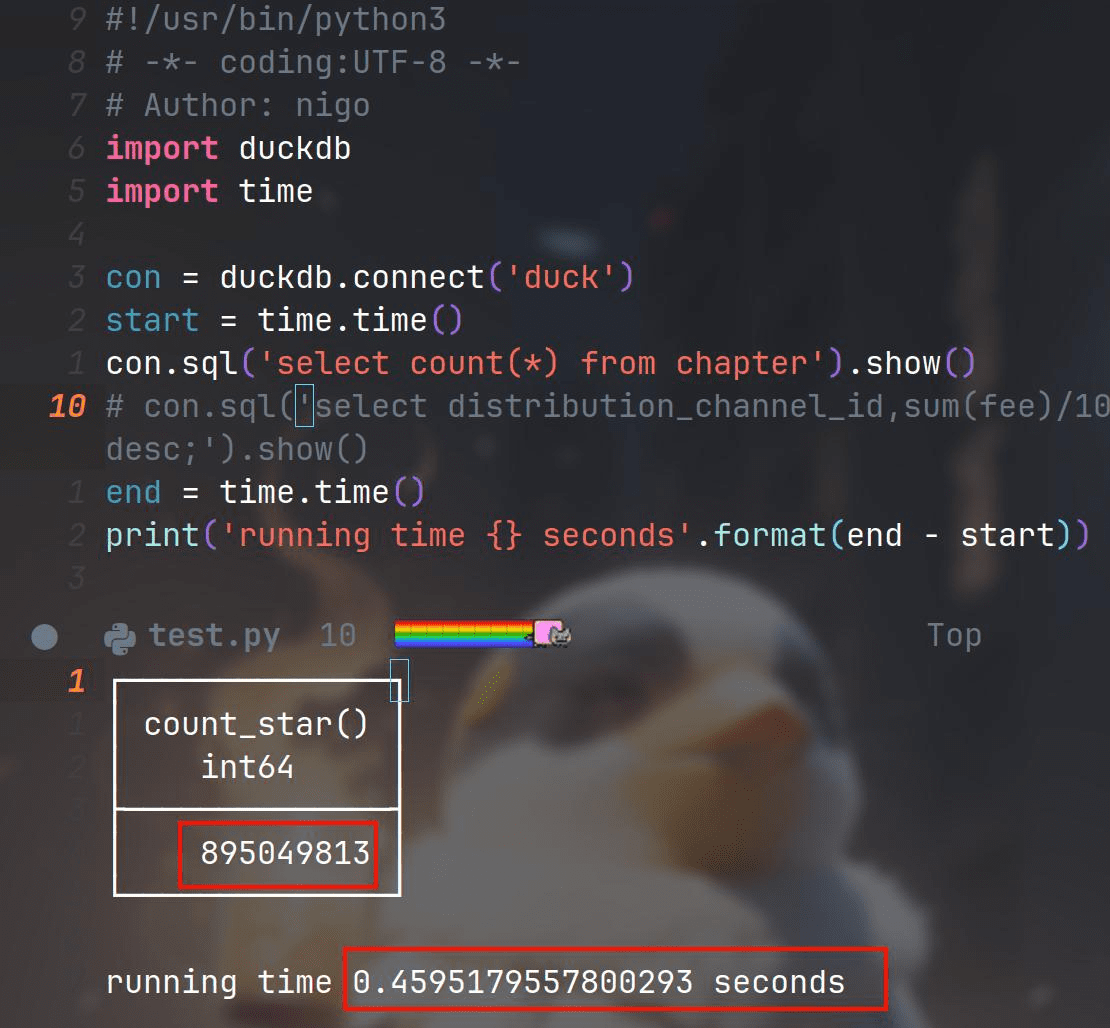
一共8.9亿行数据,跑出来花了0.45秒。
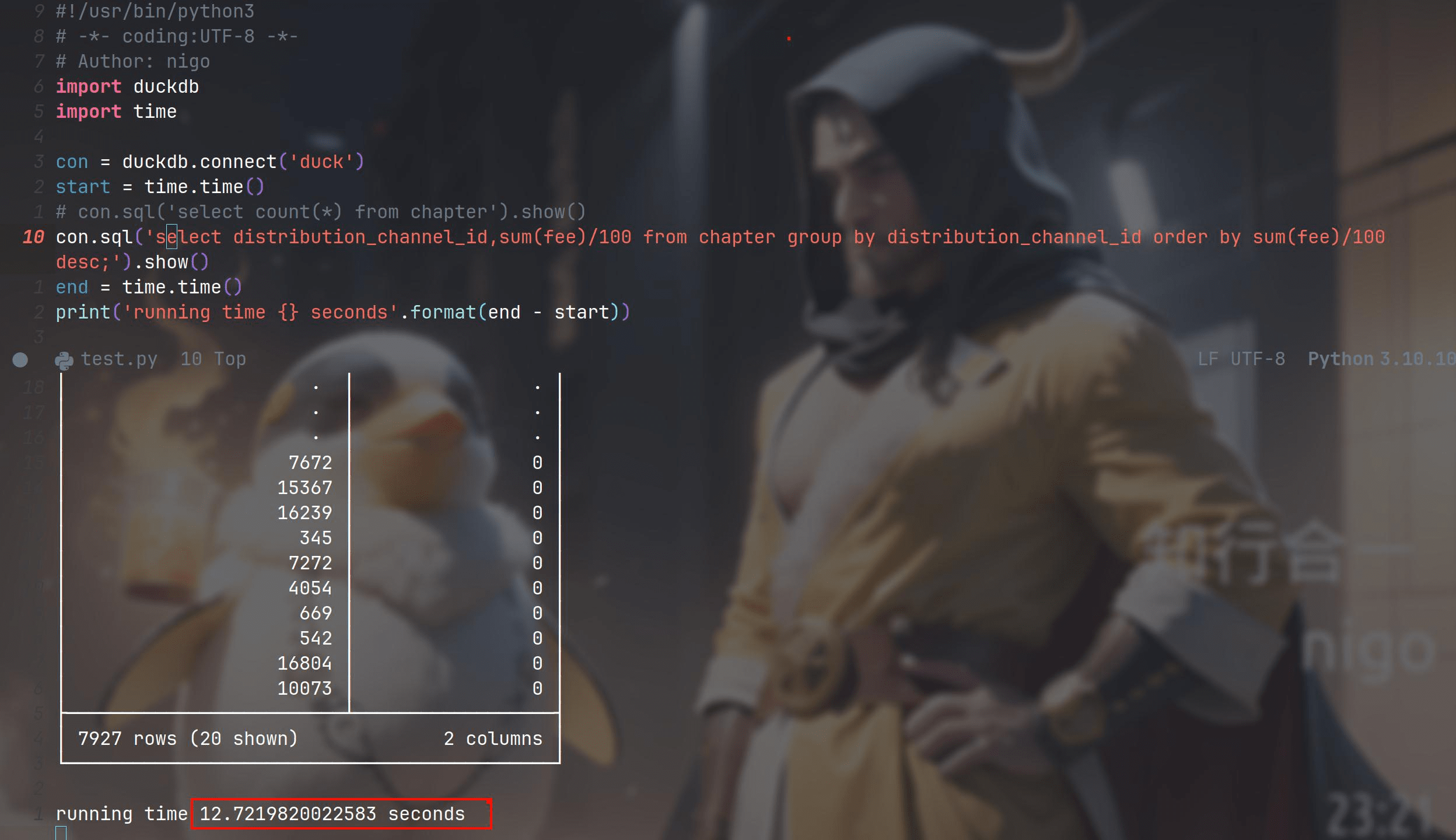
再来按一个字段聚合求和,花了12.72秒。我试过相同数据,在 clickhouse 上跑要 16 秒,居然比 clickhouse 还快,有点离谱。
结语
以上功能,我感觉无论哪个方面都可以吊打 mysql 了。
从方便程度和全平台支持角度,也可以吊打 clickhosue 了。
尤其是对我们这种在自己笔记本本地跑数据的人来说,很适用了。
我今天粗略看了下官方文档,感觉到它更强大的是和 python 的无缝链接,以及一些特殊但非常实用的独特函数。
如果有机会,我后面会出系列教程。
感觉我们部门所有人都可以抛弃 mysql 了。
官方网站:https://duckdb.org/