手工发票号拆分
上周同事在做一个项目,涉及到采购发票台账与税务系统发票的核对。
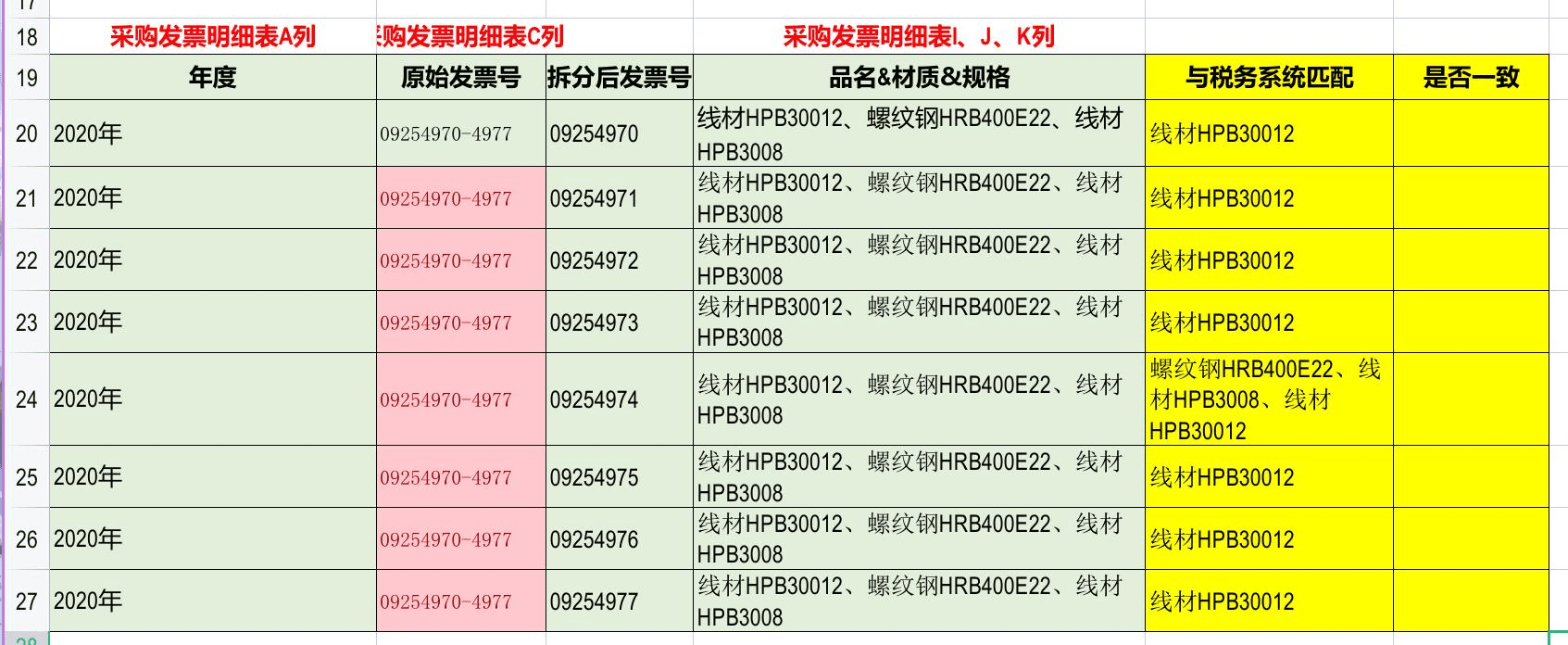
其中采购发票台账是财务手工维护的,长这样:

其中发票号是09254970-4977 ,代表着09254970 到 09254977 连续的编号,是一个范围。
而税务系统的发票号是分开的,长这样:
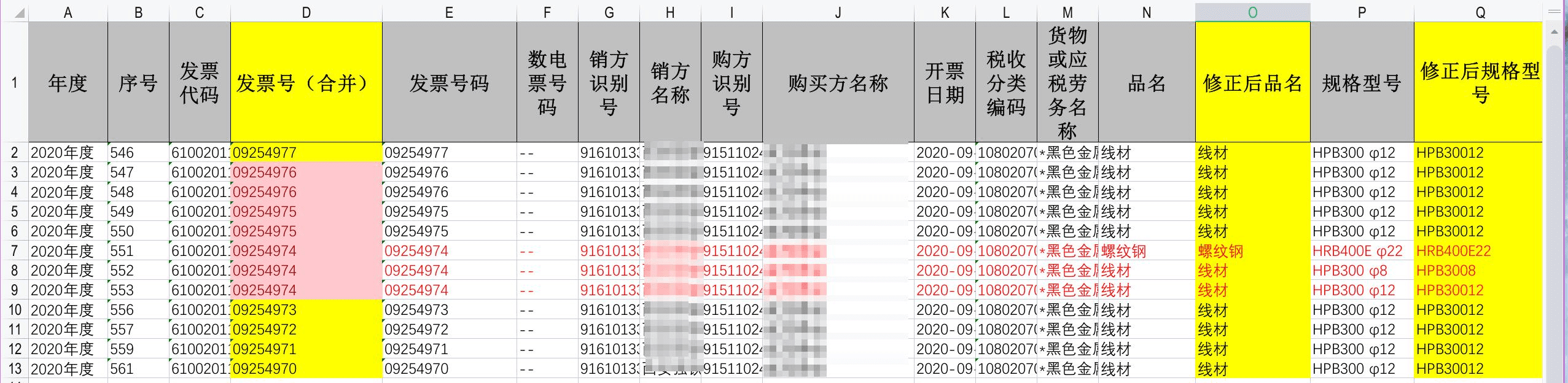
最终同事想生成这样的核对明细:
需求
她需要实现 3 个目标:
将采购发票明细表里的发票号进行拆分,并对品名及规格型号进行合并列示。
也就是将范围的发票号拆分成多行,同时之前相同发票号范围的多个规格型号合并在一起。
将税务系统发票明细里的的品名及规格型号按发票号合并列示
也就是之前品名和规格是两列,要合在一列。
将拆分合并后的采购发票明细与税务系统发票明细,根据发票号,对品名规格型号进行匹配核对。
例如:09254970-4977 ,所有的规格型号和税务系统所有规格型号作对比,只要元素相同,不论顺序,就将这个范围的发票号“是否一致”标注成“是”。
拆分逻辑编写
当然,由于采购发票明细是手工维护的,有些不规范,录入的数据存在00737934-7937、1277263-7266这种多个范围的,也存在这种21256660-6664、6666-6681第二范围只用尾数 6666 开头,连前面前缀2125都省去的情况。
所以拆分的时候,我首先需要判断是否存在顿号、,有的号先将其拆分成多个范围组,再处理每一个范围组。
def split_number(input_str):
if re.findall('、', input_str):
subs_str = input_str.split('、')
mother_str = subs_str[0]
if re.findall('-', input_str):
mother_number = mother_str.split('-')[0]
else:
mother_number = mother_str
output = []
for sub_str in subs_str:
output = output + split_number_by_flag(sub_str, mother_number)
return output
else:
return split_number_by_flag(input_str)上面的函数当我输入input_str发票号时,将判断是否有顿号,存在的话,拆分开,并获取第一个范围的数字前缀作为mother_number母号码。
这样就可以使用split_number_by_flay(input_str,mother_number='')函数分别处理单个范围组:
def split_number_by_flag(input_str,mother_number=''):
if re.findall('-',input_str):
start, end = input_str.split('-')
if len(start) < len(mother_number):
end = start[ :len(start)-len(end)] + end
start = mother_number[ :len(mother_number)-len(start)] + start
end = mother_number[ :len(mother_number)-len(end)] + end
else:
end = start[:len(start)-len(end)] + end
length = len(start)
start = int(start)
end = int(end)
output = [str(i).zfill(length) for i in range(int(start), int(end) + 1)]
return output
else:
if mother_number:
output = [mother_number[ :len(mother_number)-len(input_str) ] + input_str]
else:
output = [input_str]
return output这样我就可以完成连续发票号的拆分。
至于规格型号的对比,我只需要将发票号范围的所有规格型号存成元组,和税务系统的数据作对比,就可以判断是否一致。
完整代码
以下是完整代码,可以批量处理同事对2019-2023.6月的所有发票的拆分、核对工作。
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
# Author: nigo
import pandas as pd
from tqdm import tqdm
import re
def split_number_by_flag(input_str,mother_number=''):
if re.findall('-',input_str):
start, end = input_str.split('-')
if len(start) < len(mother_number):
end = start[ :len(start)-len(end)] + end
start = mother_number[ :len(mother_number)-len(start)] + start
end = mother_number[ :len(mother_number)-len(end)] + end
else:
end = start[:len(start)-len(end)] + end
length = len(start)
start = int(start)
end = int(end)
output = [str(i).zfill(length) for i in range(int(start), int(end) + 1)]
return output
else:
if mother_number:
output = [mother_number[ :len(mother_number)-len(input_str) ] + input_str]
else:
output = [input_str]
return output
def split_number(input_str):
if re.findall('、', input_str):
subs_str = input_str.split('、')
mother_str = subs_str[0]
if re.findall('-', input_str):
mother_number = mother_str.split('-')[0]
else:
mother_number = mother_str
output = []
for sub_str in subs_str:
output = output + split_number_by_flag(sub_str, mother_number)
return output
else:
return split_number_by_flag(input_str)
if __name__ == "__main__":
print('读取数据')
df_detail = pd.read_excel('采购发票明细表2019-2023.6-7.18版.xlsx',converters={'修正后发票号':str})
df_tax = pd.read_excel('税务系统发票明细2019-2023.6-7.18版.xlsx',converters={'发票号(合并)':str})
# 填充空值
df_detail.fillna('',inplace=True)
df_tax.fillna('',inplace=True)
# 合并规格型号
df_detail['品名材质规格'] = df_detail.apply(lambda row: str(row['修正后品名']) + str(row['材质']) + str(row['规格']),axis=1)
df_tax['品名材质规格'] = df_tax.apply(lambda row: str(row['修正后品名']) + str(row['修正后规格型号']),axis=1)
# 获取所有发票号码
invoice_numbers = df_detail['修正后发票号'].unique()
# 税务发票号与品名规格型号对应关系
number2category = {}
df_merge = pd.DataFrame()
print('建立税务明细关系')
for index,row in df_tax.iterrows():
invoice_number = row['发票号(合并)']
if invoice_number in number2category.keys():
tmp = number2category[invoice_number]
if row['品名材质规格'] not in tmp:
tmp.append(row['品名材质规格'])
tmp.sort()
number2category[invoice_number] = tmp
else:
number2category[invoice_number] = [row['品名材质规格']]
print('循环采购明细')
# 数据处理,循环采购发票明细
for invoice_number in tqdm(invoice_numbers):
try:
split_numbers = split_number(invoice_number)
except:
split_numbers = []
print(invoice_number)
df_number = pd.DataFrame()
tax_categories = []
tax_names = []
sub_df = df_detail[df_detail['修正后发票号']==invoice_number]
sub_df = sub_df.reset_index(drop=True)
categories = sub_df['品名材质规格'].unique()
categories.sort()
category = '、'.join(categories)
if split_numbers:
df_number['年度'] = [sub_df.loc[0,'年度']] * len(split_numbers)
df_number['原始发票号'] = invoice_number
df_number['拆分后发票号'] = split_numbers
else:
df_number['年度'] = [sub_df.loc[0,'年度']] * 1
df_number['原始发票号'] = invoice_number
df_number['拆分后发票号'] = '不能拆分'
df_number['品名材质规格'] = category
for no in split_numbers:
if no in number2category.keys():
tax_row_name = number2category[no]
tax_row_name.sort()
tax_categories = tax_categories + tax_row_name
tax_name = '、'.join(tax_row_name)
tax_names.append(tax_name)
else:
tax_names.append('未找到编号')
if tax_names:
df_number['与税务系统匹配'] = tax_names
else:
df_number['与税务系统匹配'] = '未找到编号'
if set(tax_categories) == set(categories):
df_number['是否一致'] = '是'
else:
df_number['是否一致'] = '否'
df_merge = pd.concat([df_merge,df_number])
df_merge.to_excel('结果.xlsx',index=False)
print('over')