主要原材料与标准BOM计算理论耗用量的匹配性
在见微数据的 IPO 问询反馈栏目搜索一下关键词“ BOM ”,可以看到出现了 147 个相关问询。
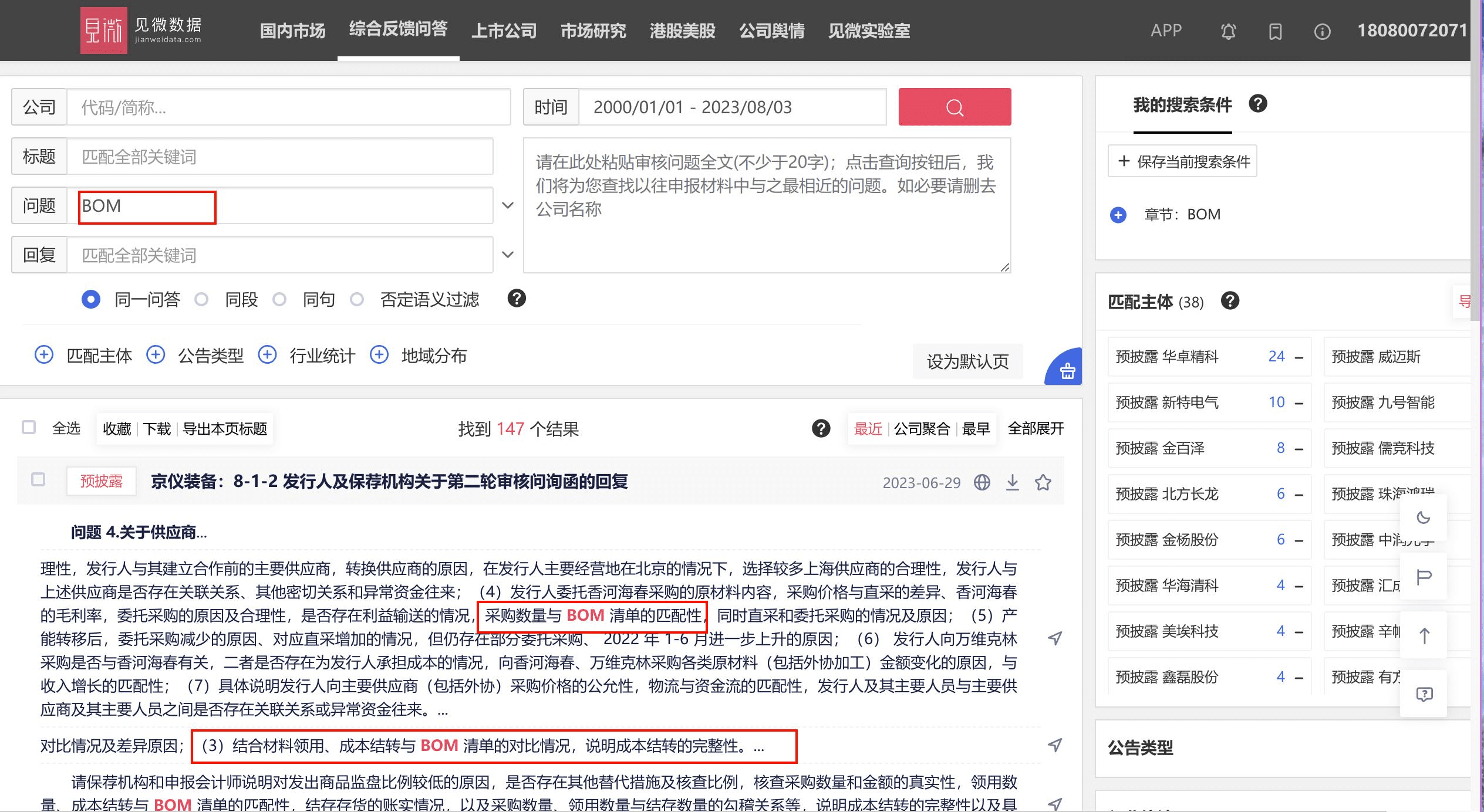
这里随便列举前几条:
1.结合材料领用、成本结转与 BOM 清单的对比情况,说明成本结转的完整性.
2.结合 BOM 清单、产品销量以及实际领用数量,说明投入产出的配比关系、成本结转完整性以及是否存在将不相关支出计入存货的情形.
3.结合主要产品的 BOM 表单物料构成,说明主要物料采购、耗用、结存与产成品销售的匹配关系.
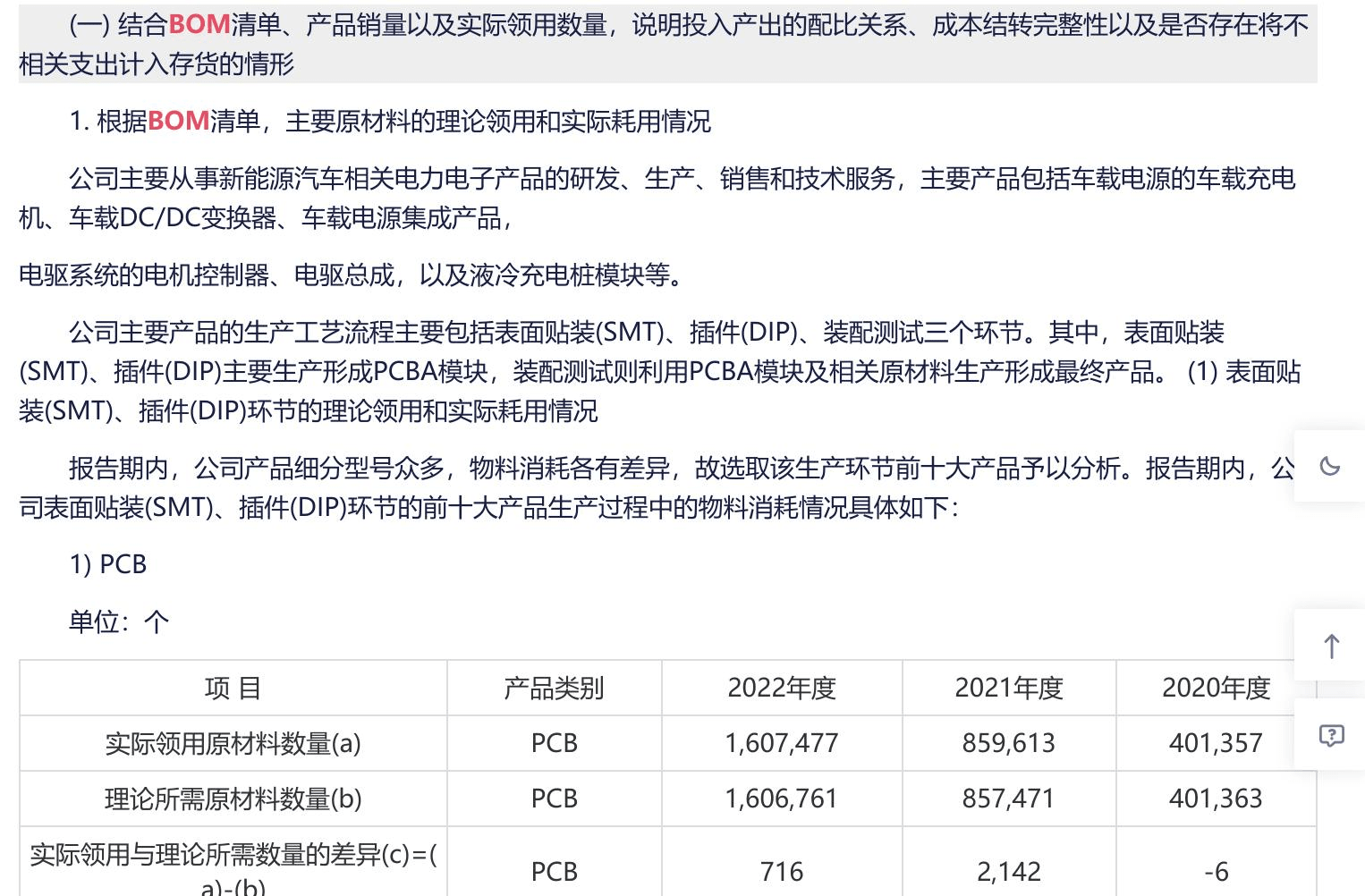
可以看出根据 BOM 计算出原材料的理论耗用量与实际耗用量,是 IPO 问询中的常见问题。
那么BOM (物料清单)是什么?
它是产品结构表,通俗点理解就是配方。
假如我们要做一盘青椒肉丝,那么它的 BOM 就是理论上需要几两肉、几两青椒、多少调味料,就是生产过程的配方。
当然,这中间还涉及到生产工艺,分成几道工序,哪个时候洗菜、哪个时候切菜、哪个时候烹饪等等。
在制造型企业中,ERP 系统会专门维护 BOM ,生产领料时一般会根据系统 BOM 计算需要多少原材料并按单领料。
那么作为审计,我们会自己动手算产成品所需要理论原材料耗用量,或者说单耗吗?
当工艺简单,只有一两道工序的时候,我们可能能做到,当工序多了后,可能只能让企业提供,我们分析复核了。
其实只要我们拿到 BOM 就可以计算出单个产成品所需要消耗的原材料数量。
下表是一个典型的 ERP 系统中的 BOM 表:
| 父物料 | 子物料 | 数量 | 单位 |
|---|---|---|---|
| A | B | 1 | EA |
| A | C | 2 | EA |
| B | D | 0.6 | KG |
这里假设我们生产一个产成品 A 需要两道工序:冲压和焊接。
冲压是将钢材加工成一定的形状。
焊接是将冲压件焊接在一起。
那么产成品 A 在焊接工序需要耗用 B 、 C 两个物料。而 B 又是通过 C 在冲压工序中制得的。
我们可以看到这里有个问题是这个 BOM 表是一张二维表,而我们产成品是多层级的。如果直接看表中产成品 A 耗用的物料是 B 和 C , 但我们真正需要看的是 A 耗用的末级物料 C 和 D.
那么我们主要解决的问题是如何根据这个 bom 二维表计算出产成品消耗的末级物料数量。
之前我写过一篇文章用 python 构建两个类:节点类和树类,完成了这个操作。
当时生成产成品只包含:未在“子物料”列出现过的父物料,自动识别为产成品。
但我发现有些企业存在一些中间产品对外销售的情况,代码生产不能包含这些中间产品。
所以,我修订了下,可以和之前一样只生成产成品的末级物料消耗量,也可以生产指定物料(包含中间产品)的末级物料消耗量。
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
# Author: nigo
import pandas as pd
class Node:
def __init__(self, name, amount=1):
self.name = name # 节点名称
self.amount = amount # 数值
self.father = None # 父节点
self.children = [] # 子节点
def add_child(self, obj):
self.children.append(obj) # 添加子节点
def add_father(self, obj):
self.father = obj # 添加父节点
def terminal(self,name=True):
"""末级节点"""
terminal_list = [] # 创建末级节点列表
for node in self.children: # 遍历子节节点
if node.children: # 若子节点有子节点
terminal_list += node.terminal(name) # 递归函数
else:
if name:
terminal_list.append([name,node.name,node.amount]) # 添加到末级节点列表
else:
terminal_list.append([node.name,node.amount]) # 添加到末级节点列表
return terminal_list
class Tree:
def __init__(self, df,tops=[]):
self.trees = []
self.init(df,tops) # 初始化
def init(self, df,tops):
father_list = df.iloc[:, 0] # df第一列为父节点名称
child_list = df.iloc[:, 1] # df第二列为子节点名称
if not tops:
# 父节点中未出现在子节点的为顶级节点
tops = [i for i in father_list if i not in list(child_list)]
# 指定了父节点就用指定的。
tops = list(set(tops))
relation = {} # 层级对应关系
for index, row in df.iterrows(): # 循环dataframe每一行
father = row[0] # 父节点名称
child = row[1] # 子节点名称
amount = row[2] # 子节点值
if father in relation.keys():
children = relation[father]
children.append({'name':child,'amount':amount})
relation[father] = children
else:
relation[father] = [{'name':child,'amount':amount}]
self.relation = relation
for top in tops:
if top in self.relation.keys():
self.trees.append(self.make_tree(top,1))
def make_tree(self, top, amount):
"""根据顶级节点建立树状关系"""
father_node = Node(top,amount) # 创建父节点
for child in self.relation[top]: # 遍历父节点对应的所有下一层级
if child['name'] in self.relation.keys(): # 如果child有下一层级
child_node = self.make_tree(child['name'],child['amount']*amount) # 调用递归函数
child_node.add_father(father_node) # 给子节点添加父节点
father_node.add_child(child_node) # 给父节点添加子节点
else: # 如果child没有下一层级
child_node = Node(child['name'],child['amount']*amount) # 创建子节点
child_node.add_father(father_node) # 给子节点添加父节点
father_node.add_child(child_node) # 给父节点添加子节点
return father_node
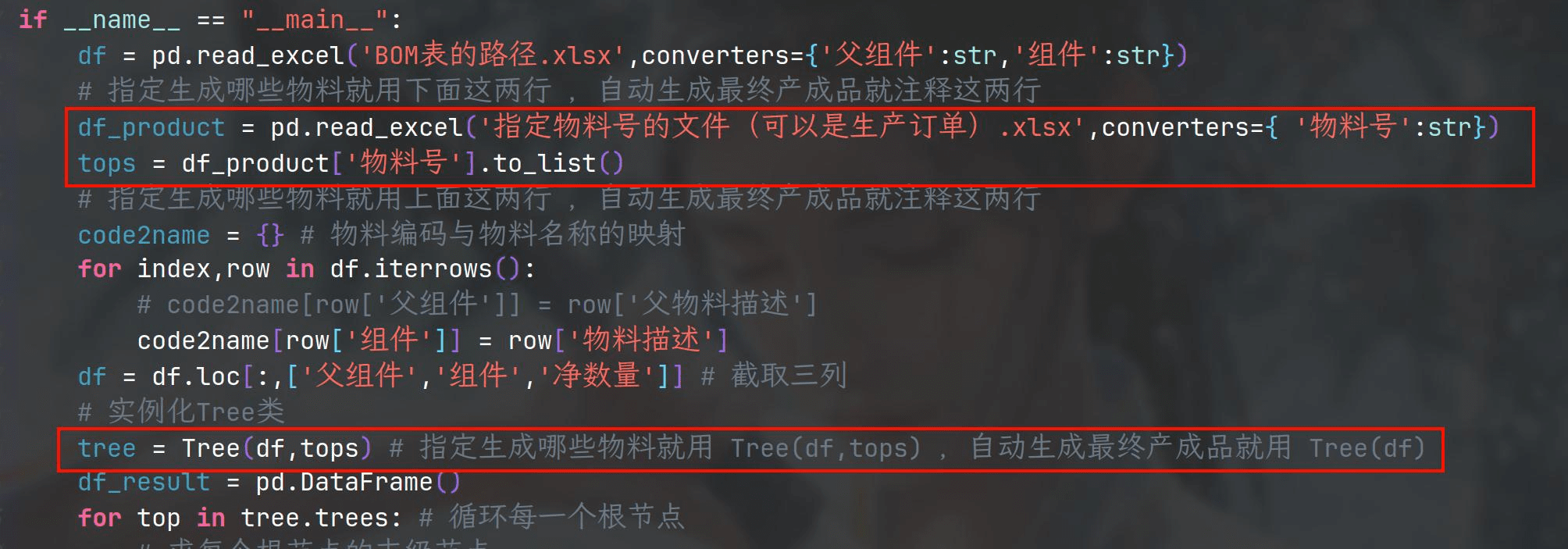
if __name__ == "__main__":
df = pd.read_excel('BOM表的路径.xlsx',converters={'父组件':str,'组件':str})
# 指定生成哪些物料就用下面这两行 ,自动生成最终产成品就注释这两行
df_product = pd.read_excel('指定物料号的文件(可以是生产订单).xlsx',converters={ '物料号':str})
tops = df_product['物料号'].to_list()
# 指定生成哪些物料就用上面这两行 ,自动生成最终产成品就注释这两行
code2name = {} # 物料编码与物料名称的映射
for index,row in df.iterrows():
code2name[row['父组件']] = row['父物料描述']
code2name[row['组件']] = row['物料描述']
df = df.loc[:,['父组件','组件','净数量']] # 截取三列
# 实例化Tree类
tree = Tree(df,tops) # 指定生成哪些物料就用 Tree(df,tops) ,自动生成最终产成品就用 Tree(df)
df_result = pd.DataFrame()
for top in tree.trees: # 循环每一个根节点
# 求每个根节点的末级节点
df_tmp = pd.DataFrame(top.terminal(top.name),columns=['父组件','组件','数量'])
# 合并dataframe
df_result = pd.concat([df_result,df_tmp])
# 根据物料代码添加物料名称
df_result['父组件名称'] = ''
df_result['组件名称'] = ''
df_result = df_result.reset_index(drop=True)
for index,row in df_result.iterrows():
if row['父组件'] in code2name.keys():
df_result.loc[index,'父组件名称'] = code2name[row['父组件']]
df_result.loc[index,'组件名称'] = code2name[row['组件']]
df_result.to_excel('你需要生成文件的路径.xlsx',index=False)
print(df_result)上面的中文名称基本上是列名,只需要修改成你的数据的列名就可以了。
代码是需要将你想生产的物料号给df_product,如果不想指定,可以将下面三行修改下。
执行就可以生成出产成吕需要消耗的末级原材料数量:
| 父组件 | 组件 | 数量 | 父组件名称 | 组件名称 |
|---|---|---|---|---|
| A | C | 2 | xxx | xxx |
| A | D | 0.6 | xxx | xxx |
当然,这里只是个 2 阶的 BOM ,实际上 100 阶,1000 阶对于这个代码来说都是一样的。
当我们有了这个单耗后,直接乘以全年的生产数量就可以得到理论耗用量了。
再去和原材料实际领用量对比即可。
虽然我们直接可以算出所有产成品对应所有原材料的理论消耗量,但我们一般可能只会看主要原材料,比如就看钢材。
我们就只筛选并合计出钢材的理论耗用量,再和领用量、采购量做对比,分析其差异率及合理性。
最后,我想说很多制造企业只管好了采购端和销售端,中间生产过程就是一锅粥。
产生原因可能是管理的精细化程度不够,或者老板觉得毛利率高,压根就不想费这个功夫算那么清。
也可能 ERP 与企业实际管理流程不匹配,导致未按标准作业进行。
要系统能解决问题的前提是企业流程的标准化,管理问题没有理清楚,ERP 实施很大概率也会失败。