metabase数据分析及可视化-智能建表
上一篇我们对开源免费的 BI 工具 MetaBase 进行了介绍。
在开始正式学习之前,我们需要解决最重要的一个问题:导数。
我们本节将介绍,如何根据数据文件创建正确数据类型的表,并将数据导入数据库。
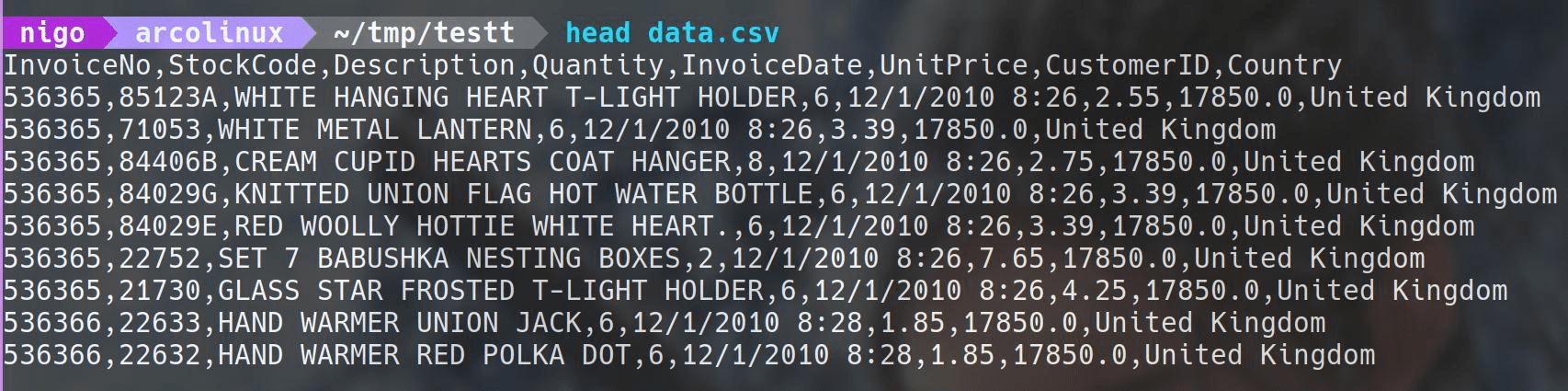
例如,我有一个data.csv文件,数据如上图所示。
很多朋友喜欢使用 Navicat 的导入向导来导数,确实相对来说,它是比较简单方便的。
但是有一个问题是,就算我们用导入向导,如果想后续使用 MetaBase ,就需要设置正确的数据类型,否则 MetaBase 无法对文本进行计算。
那么我们就需要手工一个一个的修改数据类型了,这就非常慢。尤其是当字段特别多的时候,修改数据类型就能浪费不少时间。
自动建表导数脚本
这里让 chatgpt 给我写了一个 Python 脚本,让它能一键完成。

我们运行 Python 代码:
python3 data2sql.py输入表名称
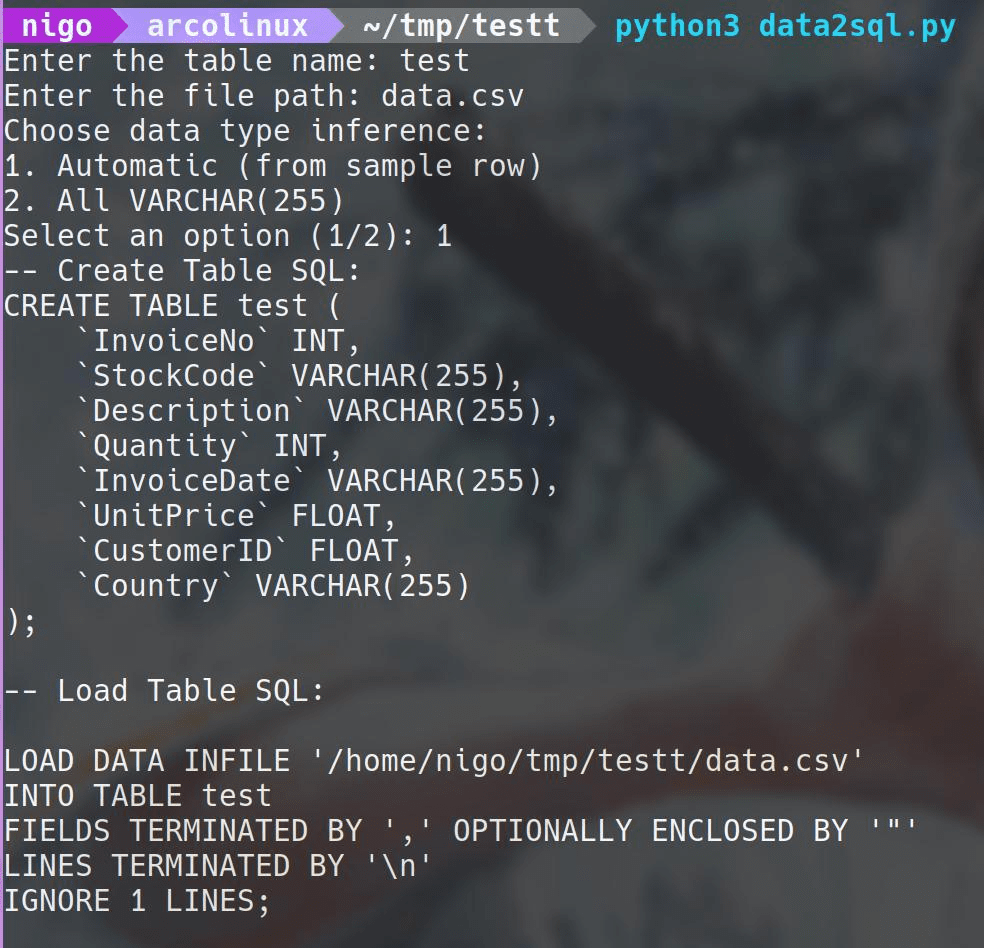
运行代码后,会出现提示,输入想创建的表的名称:例如我们输入 test
Enter the table name: test输入数据文件路径
接着会提示,我们的数据文件路径:例如我们输入 data.csv
Enter the file path: data.csv选择数据类型
这里会提示两个选项:
- 是根据数据文件第二列的数据自动生成类型。
- 是全部设置成varchar(255)文本类型。
例如我们输入 1 ,让其自动根据数据设置类型:
Choose data type inference:
1. Automatic (from sample row)
2. All VARCHAR(255)
Select an option (1/2): 1完事后,就会打印出建表语句和导数语句,同时该语句已经复制到粘贴板上,因此,我们只需要在 Navicat 等图形化工具中Ctrl+v粘贴语句,运行即可。
整个过程只需要几秒钟,实际上能比导入向导快不少时间。
数据量越大,节约的时间越多。
细心的朋友会发现 InvoiceDate 字段的值12/1/2010 8:26并没有识别成DateTime格式。
当然我们可以修改data2sql.py中 guess_data_type() 函数的正则表达式,让其能适配这种格式,但实际上就算我把该字段设置成datetime类型,导入 mysql 时并不能正确识别。
这就需要我们导入前对该日期格式进行数据清洗。
对于文本文件的数据数据清洗,我感觉最好用的还是 Linux 系统终端自带的一些命令,它们可以非常简洁、高效的完成处理。
然而,绝大多数同事都是使用的 Windows 系统,那么可以在 Windows 系统上使用 Linux 终端命令吗?
答案是可以的!
下一节,我们将先介绍如何在 Windows 上使用 Linux 终端命令,并完成数据清洗工作。
要知道,数据清洗工作其实能占不少时间的,而且这方面的资料是相对比较少一点的。
我将把平时遇到并总结的经验分享读者,我相信对于平时做数据分析的朋友,会有一些帮助。
脚本代码
上面用的data2sql.py文件代码在运行前,需要先安装使用到的 pandas 和 clipboard 库。
安装方法:
pip install pandas clipboarddata2sql.py 的完整代码如下:
#!/usr/bin/python3
# -*- coding:UTF-8 -*-
# Author: nigo
import pandas as pd
import re
import clipboard
import os
def guess_data_type(value):
if re.match(r'^\d+$', value): # Check for integer
return 'INT'
elif re.match(r'^\d+\.\d+$', value): # Check for float
return 'FLOAT'
elif re.match(r'^\d{4}-\d{2}-\d{2}$', value): # Check for date (YYYY-MM-DD)
return 'DATE'
elif re.match(r'^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}$', value): # Check for datetime (YYYY-MM-DD HH:MM:SS)
return 'DATETIME'
else:
return 'VARCHAR(255)' # Default to string type
def generate_create_table_sql(table_name, header, sample_row):
create_table_query = f"CREATE TABLE {table_name} (\n"
for column_name, value in zip(header, sample_row):
data_type = guess_data_type(str(value)) # Convert value to string before guessing data type
create_table_query += f" `{column_name}` {data_type},\n"
create_table_query = create_table_query.rstrip(",\n") + "\n);"
return create_table_query
def generate_load_table_sql(table_name, file_path):
abs_file_path = os.path.abspath(file_path)
load_table_query = f"""
LOAD DATA INFILE '{abs_file_path}'
INTO TABLE {table_name}
FIELDS TERMINATED BY ',' OPTIONALLY ENCLOSED BY '"'
LINES TERMINATED BY '\\n'
IGNORE 1 LINES;
"""
return load_table_query
def generate_create_table_sql_varchar(table_name, header):
create_table_query = f"CREATE TABLE {table_name} (\n"
for column_name in header:
create_table_query += f" `{column_name}` VARCHAR(255),\n"
create_table_query = create_table_query.rstrip(",\n") + "\n);"
return create_table_query
def main():
table_name = input("Enter the table name: ")
file_path = input("Enter the file path: ")
df = pd.read_csv(file_path, nrows=1) # Read only the first row to get column names and sample data
header = df.columns.tolist()
sample_row = df.iloc[0].tolist()
# User choice for data type inference
data_type_choice = input("Choose data type inference:\n1. Automatic (from sample row)\n2. All VARCHAR(255)\nSelect an option (1/2): ")
if data_type_choice == '1':
create_table_sql = generate_create_table_sql(table_name, header, sample_row)
elif data_type_choice == '2':
create_table_sql = generate_create_table_sql_varchar(table_name, header) # Create all fields as VARCHAR(255)
else:
print("Invalid choice.")
return
load_table_sql = generate_load_table_sql(table_name, file_path)
print("-- Create Table SQL:")
print(create_table_sql)
print("\n-- Load Table SQL:")
print(load_table_sql)
try:
# Copy load_table_sql to clipboard
clipboard.copy(create_table_sql+load_table_sql)
print("\nLoad Table SQL has been copied to the clipboard.")
except Exception as e:
print("\nError copying to clipboard:", e)
if __name__ == "__main__":
main()脚本及数据下载
将本文使用的data2sql.py脚本文件,以及示例数据data.csv文件供读者下载,练习。
https://wwds.lanzouq.com/i1iGw15ob2fe
虽然本文的导数脚本是针对 mysql 的,实际上大家可以修改去适用于其它数据库。
如果对 mysql 和 navicat 不了解的朋友,可以先看之前的相关文章。