审计场景下合同关键信息批量提取
在审计过程中,我们会检查财务凭证对应的合同、发票等原始凭证,一般情况下我们是通过审计抽样选取样本检查。
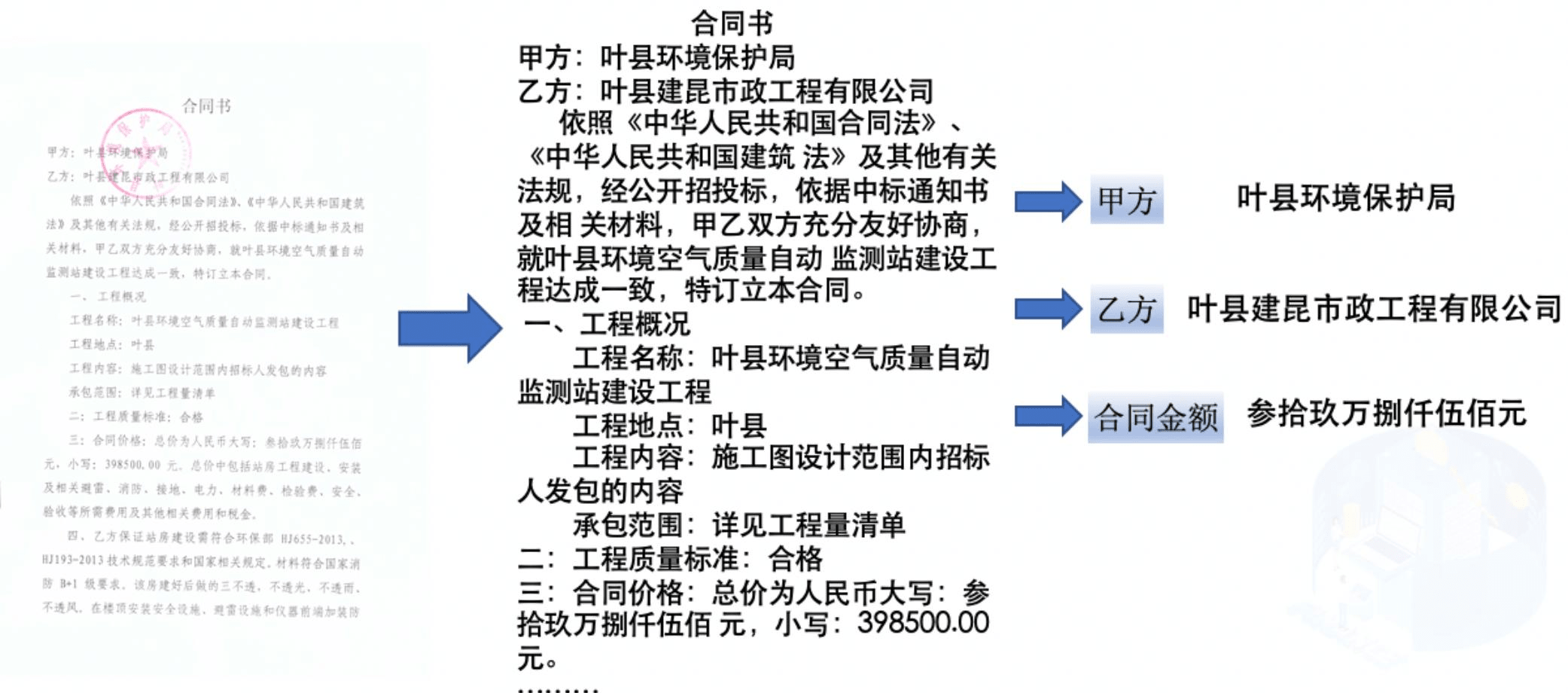
检查纸质合同或者扫描件比较麻烦,因为我们需要从大量文本信息中阅读交易方、合同金额、付款进度等关键信息。
虽然这个过程麻烦,但正常情况下我们检查的样本量不会很多,所以我们很少思考这个过程是否能够用技术手段提高效率。
一旦样本量很大,或者一些专项项目需要对所有合同进行审核、清查时,这将花费大量人力做基础工作。
正好有朋友遇到这样一个专项项目,企业连合同台账都没有,只有一堆 PDF 的合同扫描件,需要从这些合同中提取出:
甲方、乙方、合同金额 这样的关键信息,录入到 Excel 中。
我正好在百度飞桨官网上看到有这样的项目教程:
网址:https://aistudio.baidu.com/projectdetail/4434018?contributionType=1
我 Fork 了项目,跟着练习运行,中间各种报错,最后解决了,跑通了,这里作一下记录。
实现原理
整个过程实际上分成两步:
- 将图片信息利用 paddleocr 识别成文本。
- 将文本信息利用 paddlenlp 提取出关键信息,并返回结构化数据。
整个过程都是使用的百度飞桨开源模型 paddlepaddle 实现,可以部署在本地免费使用。
安装相关包
在运行代码前,我们需要先安装下面几个包:
- paddlepaddle
- paddleocr
- paddlenlp
- opencv-contrib-python
熟悉 python 的话应该知道使用pip包管理器安装:
pip3 install opencv-contrib-python==4.4.0.46 paddleocr paddlepaddle-gpu paddlenlp安装后,我在笔记本上运行代码的时候一直报错,主要原因是paddlepaddle和 paddlenlp 的版本问题。
( 注:网上提示 paddlepaddle 和 paddlenlp 版本号要一致 )
我从最新的2.6.0版本一直往下降,降到了2.4.2版本才成功。
所以,实际上在我的笔记本上需要指定版本号安装:
pip3 install opencv-contrib-python==4.4.0.46 paddleocr paddlepaddle==2.4.2 paddlenlp==2.4.2而我使用台式机用的paddlepaddle-gpu就不存在这个问题(没有指定版本号,直接安装最新的就可以用)。
图片信息识别成文字
我们以这张图片为例:

from paddleocr import PaddleOCR, draw_ocr
from PIL import Image
import cv2
import numpy as np
import matplotlib.pyplot as plt
from paddlenlp import Taskflow
# paddleocr目前支持中英文、英文、法语、德语、韩语、日语等80个语种,可以通过修改lang参数进行切换
ocr = PaddleOCR(use_angle_cls=False, lang="ch", det_db_box_thresh=0.3, use_dilation=True)
# 印章部分造成的文本遮盖,影响了文本识别结果,因此可以考虑通道提取,去除图片中的红色印章
#读入图像,三通道
image=cv2.imread("./test_img/hetong2.jpg",cv2.IMREAD_COLOR) #timg.jpeg
#获得三个通道
Bch,Gch,Rch=cv2.split(image)
#保存三通道图片
cv2.imwrite('blue_channel.jpg',Bch)
cv2.imwrite('green_channel.jpg',Gch)
cv2.imwrite('red_channel.jpg',Rch)
# 合同文本信息提取
# 合同照片的红色通道被分离,获得了一张相对更干净的图片,此时可以再次使用ppocr模型提取文本内容
img_path = './red_channel.jpg' # 使用红色通道图片排除印章影响
result = ocr.ocr(img_path, cls=False)
# 可视化结果,不想可视化可以注释下面几行代码
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result[0]]
txts = [line[1][0] for line in result[0]]
scores = [line[1][1] for line in result[0]]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
im_show = Image.fromarray(im_show)
vis = np.array(im_show)
im_show.show()
#忽略检测框内容,提取完整的合同文本:
txts = [line[1][0] for line in result[0]]
all_context = "\n".join(txts)
print(all_context)( 注:在作者源代码的变量 result 列表修改为取第一个元素,即需要将result修改成result[0]才可以,否则会报错 )
上面代码考虑了图片扭曲的影响,也排除红色印章对文本遮挡的影响,运行后,会出现可视化的图片:

可以看到 paddleocr 对文本进行了很好的识别。
打印出识别的文本信息 all_context:

关键信息抽取
关键信息抽取使用了 paddlenlp 的模型,我们可以直接开箱即用,而不需要任何自定义训练。
我们只需要告诉它我们需要哪几个字段,将其赋值给schema变量即可:
比如,我想要"甲方",“乙方”,“总价”,“大写”,“小写”,“项目"这 6 个字段,那么可以写代码:
schema = ["甲方","乙方","总价","大写","小写","项目"]
ie = Taskflow('information_extraction', schema=schema)
ie.set_schema(schema)
result = ie(all_context)
print(result)运行后,它会根据我们需要的字段信息,在前一步提取出的all_context文本中抽取最适合的。

作者原文提到了三个方法可以对关键信息提取调优:
- 修改 schema
- 添加正则方法
- 标注小样本微调模型
可以看出我们是可以在这个基础模型上根据我们场景和数据特点进行标注样本微调的,我感觉这个挺重要的。这能让我们在一些垂直领域提高精准度。
具体做法可以参考作者原文的相关文章,我还没有学习。
关于执行效率
以上是单个图片的识别,在笔记本上跑没有什么问题。
但我们知道合同文件是很多页的。
我拿了一个 60 多页的合同 pdf ,用 python 切分成 60 多张图片,然后循环将其识别成文本信息并拼接在一起。
这个过程用笔记本的 CPU 跑,非常慢。具体没有计算时间,我估计有 10 分钟。
再把拼接的文本提取关键信息,这个过程直接把我的电脑搞死机了。
所以,如果想用 CPU 跑基本上不具有现实意义。
我再把代码远程放在我家里的台式机上,台式机是 3080 显卡,将之前安装的paddlepaddle换成paddlepaddle-gpu。使用 gpu 跑的时候,从识别到提取信息, 60 页的合同只需要 15 秒就可以处理完毕。
如果后面批量处理多个pdf,不考虑模型加载的时间, 60 多页的合同实际上只需要 10 秒钟。
这就比人去统计快得多了,具备了现实意义。
所以,后面我会尝试下批量处理大量合同的场景。
另外百度飞桨上还有发票识别、表格信息提取等本地模型教程。
如果能学会自己训练微调的话,那么在审计场景中很多纸质单据、票据都能够批量识别,提取出关键信息。
这将具有很大的运用场景。
审计过程中,大量时间耗费在这些基础工作中了,如果你被这些工作折磨过,我相信应该会深有体会。
最后,我想说效率往往最关键的不是技术,而是具有效率的思维。
有效率思维的人,其实无论级别高低、技术高低,他都能思考这项工作是不是有更高效的处理方式。
有这样的思维,最终才可能用技术推动行业的变革和进步。
最后,我将修正过的代码放在网盘供大家下载:
https://wwds.lanzouq.com/iyG5i16uy2cb
压缩文件中:
作者源代码:main.ipynb 得用jupyter notebook打开。
精简后的:test.py 可以直接用 python 执行。
参考文章:
https://aistudio.baidu.com/projectdetail/4434018?contributionType=1