注册会计师《会计》分录荟萃
目录
昨天CPA备考群群友向我求助,想将2023的会计分录荟萃做成Anki卡牌,方便平时工作中记忆。
原始文档是 word 版本:
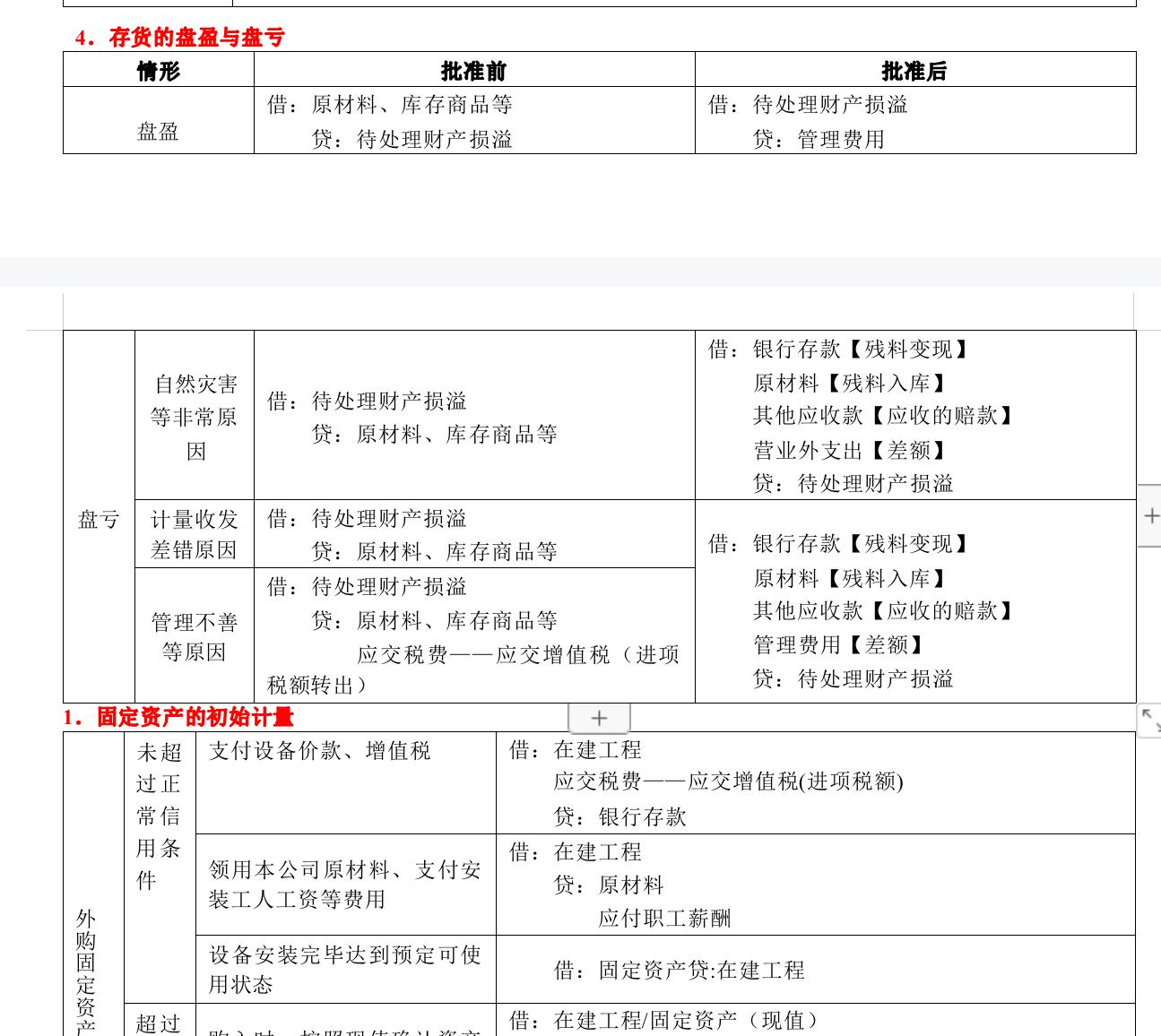
基本上就是一道题目,一个表格。
最后批量做出的效果如下:
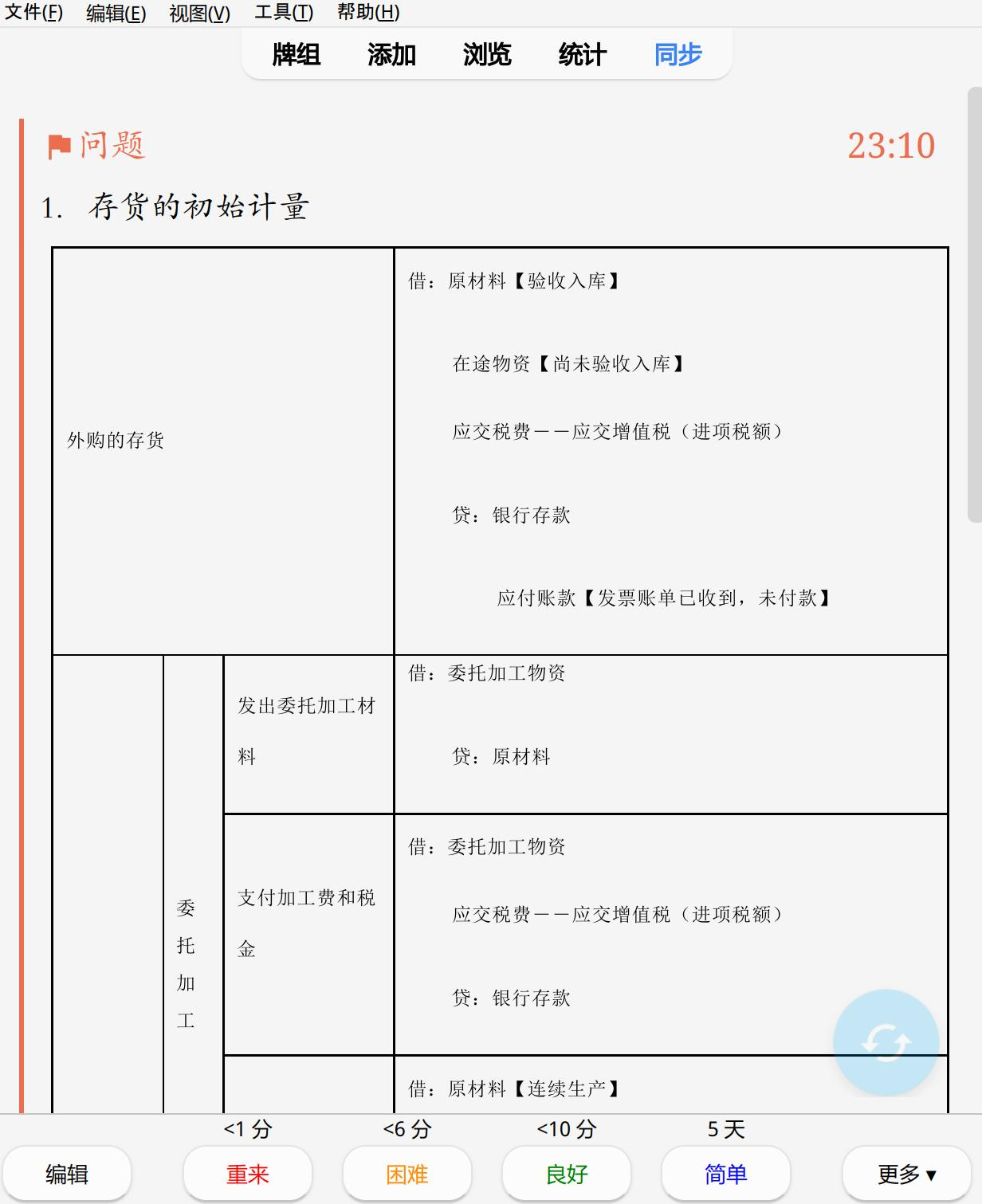
制作过程
通过 chatgpt 对话帮我写了个 python 代码,直接从 word 里提取出“问题-表格”,其中表格转换成 html 格式,批量写入到 anki 中(需要安装 anki-connect 插件)。
但这样对于合并单元格不能很好处理,导致效果不好。
所以改变思路,分成三步:
- 将 word 文档另存为 html 文档
直接利用 word 的功能,将其转换成 html 文档,这样对于合并单元格就不会有问题了。
python 提取 html 文档中的问题和表格
循环批量制卡。(当然另存为 csv 文档导入 Anki 也可以)
代码
通过和 chatgpt4 友好对话,让它帮我写出下面代码。
其中 deck_name ,template_name ,fields 修改成你自己的实际参数。
( 注意:需要先在 Anki 创建个和 deck_name 变量相同的牌组)
from bs4 import BeautifulSoup
import requests
def extract_tables_and_titles(html_content):
soup = BeautifulSoup(html_content, 'html.parser')
tables = soup.find_all('table')
titles = []
for table in tables:
# 初始化标题为空字符串
title = ""
# 检查表格的前一个兄弟节点
prev_sibling = table.previous_sibling
while prev_sibling:
# 如果找到文本节点,则提取文本并停止循环
if prev_sibling.name == 'p':
title = prev_sibling.get_text(strip=True)
break
# 否则,继续检查前一个兄弟节点
prev_sibling = prev_sibling.previous_sibling
titles.append(title)
return titles, tables
# 读取HTML文件(把word另存为html格式)
with open("注册会计师《会计》分录荟萃.html", "r", encoding="gb2312") as file:
html_content = file.read()
titles, tables = extract_tables_and_titles(html_content)
# 卡牌名称
deck_name = '表格'
# 模板名称
template_name = "Analysis-Basic"
anki_connect_url="http://127.0.0.1:8765"
# 打印每个标题和对应的表格HTML
for title, table in zip(titles, tables):
payload = {
"action": "addNote",
"version": 6,
"params": {
"note": {
"deckName": deck_name,
"modelName": template_name,
"fields": { # 这里是对应卡片模板对应字段的映射
'问题':title,
'答案':str(table)
},
"tags": ''
}
}
}
response = requests.post(anki_connect_url, json=payload)
print("Add Note Response:", response.text)其中难点是需要让它解决,两个表格中间的文字才是下个表格的问题,因为可能会存在没有标题的情况。
这个代码应该通用于:一个文字,一个表格的情形。
这样就不用手工,一个一个利用插件添加了。
卡牌下载
我将 word 文档和代码以及做好的卡牌供大家下载,学习。
下载链接: